Echtzeit-Programmierung,
plus Java public domain experimentelle Software
Sergio Montenegro (.)
GMD-FIRST (http://www.first.fhg.de)
Rechnerunterstützte Regelung und Steuerung wird in der Regel 1 mit parallel laufenden echtzeit-reaktiven Tasks implementiert. Die reaktiven Tasks reagieren auf externe und Zeit-Ereignisse. Dafür wird ihr Durchlauf in drei Phasen, die nach Eintreten eines Ereignisses (Interrupt) aktiviert werden (aperiodische Tasks) oder periodisch durchlaufen, aufgeteilt:
- 1) Messen (die Sensoren lesen): um den Zustand der gesteuerten Anlage zu ermitteln.
- 2) Berechnen: Die Reaktion der Steuerung auf die Ereignisse wird berechnet.
- 3) Ausgeben (Schreiben auf die Aktuatoren): Die berechnete Reaktion wird in die Tat umgesetzt.
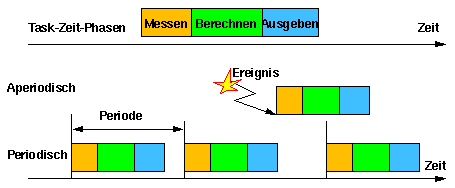
Die Perioden und die Enge der Zeitanforderungen sind unterschiedlich für Regelungs- und für Steuerungsaufgaben. Die Regelungsaufgaben haben eine hohe Frequenz und einfache Berechnungen (dies bedeutet nicht eine einfache Entwicklung!). Die Regelungsfrequenz kann zwischen 100 Mal/Sek und 30K Mal/Sek liegen und die Regelung muß auf ein Interrupt-Aufkommen von bis zu 10K Mal/Sek reagieren können, aber ihre Ausführungszeit kann so kurz wie 20 Mikrosekunden sein. Die Steuerungsaufgaben haben dagegen eine niedrigere Frequenz aber komplexere Berechnungen. Ihre Frequenz kann zwischen 1 Mal/Sek und 1000 Mal/Sek liegen. Die Berechnungen können auch komplexe Operationen von Neuronalen Netzen und Expertensystemen beinhalten, was sehr zeitaufwendig ist. Es gibt langsamere Ausnahmen, wie z.B. ein Wecker, der erst in einigen Stunden klingeln soll. Es gibt auch schnellere Ausnahmen, wie z.B. die Regelungsfrequenz eines Elektronenbeschleunigers bis zu 1M Mal/Sekunde sein kann. Diese Regelung ist kaum noch mit Software zu erledigen.
Deswegen unterscheidet man je nach verfügbarer Zeit zwischen echte-Echtzeit (real real-time), wo die Zeit sehr knapp gemessen ist, und lockere-Echtzeit, wo die Reaktionen mehr als genügend Zeit zur Verfügung haben.
Die Korrektheit der Echtzeit-Tasks besteht nicht nur darin, einen korrekten Output-Wert zu generieren, sondern auch zum richtigen Zeitpunkt, und nicht einfach "so schnell wie möglich", z.B. der Wecker, der um 6:15 klingeln soll. Sein Output ist das Klingeln, aber nicht irgendwann, sondern ca. um 6:15. Es muß auch nicht genau um 6:15 sein, es gibt ein Reaktionszeitfenster mit einer gewissen Toleranz, z.B. das Klingeln zwischen 6:12 und 6:18 ist akzeptabel. Das Ende der Zeitfenster ist die Deadline (nicht später). Meistens wird im Echtzeit Kontext nur von Deadlines gesprochen und der Anfang der Zeitfenster wird ignoriert. Dies kann zu Timing-Fehlern führen, die wiederum zu einem Anlagenausfall oder Versagen führen können.
Die Echtzeit-Tasks können abhängig von ihrer Zeitkritikalität folgendermaßen klassifiziert werden:
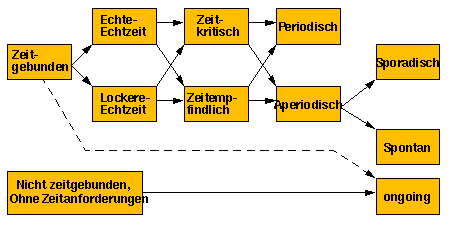
1) Zeitkritisch oder harte Echtzeit (zeitgebunden):
Diese Tasks haben feste Deadlines oder Reaktionszeitfenster, die nicht verpaßt werden dürfen. Wenn die Reaktion nicht in den vorgesehenen Reaktionszeitfenstern stattfindet, ist es ein Fehler, der zum Systemausfall führt, z.B das Ausschalten der Wärmequelle eines Kessels bevor er explodiert: Das Ausschalten eine Millisekunde nach dieser harten Deadline hilft nicht mehr. Aber sehr oft kann nach dem (Timing-) Fehler noch eine Ausnahmebehandlung --fail safe oder fail soft-- eingeleitet werden, die das System in einen stabilen, sicheren Ausfallzustand bringt, z.B. das Öffnen eines Sicherheitsventils (aber immer noch vor der Explosion). Danach sind auch Recovery und Restart möglich. Aber in jedem Fall stehen wir zuerst vor einem Systemausfall. Auch eine zu frühe Reaktion kann einen Systemausfall bedeuten, z.B. das Anlenken eines Fahrzeuges noch bevor die Kurve erreicht wird, kann einen Systemausfall bedeuten.
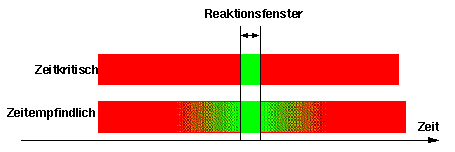
2) Zeitempfindlich oder weiche Echtzeit (auch zeitgebunden):
Das Reaktionszeitfenster ist nicht so hart definiert, sondern so wie die Fuzzy-Mengen. Das Reaktionszeitfenster ist eher als eine Wunschzeit zu interpretieren. z.B. das Einschalten einer Heizungsanlage, wenn die Temperatur unter 19 Grad liegt, ist nicht so zeitkritisch. Wenn es einige Sekunden oder sogar Minuten später oder früher stattfindet bedeutet es nicht, daß das System ausgefallen ist.
Vorsicht ist geboten, wenn zeitempfindliche Tasks das Timing von zeitkritischen Tasks beeinflussen können. In diesem Fall sind auch diese als zeitkritisch zu betrachten.
3) Ohne Zeitangaben oder Ongoing (nicht zeitgebunden):
Diese Tasks brauchen nur ihre Ergebnisse zu liefern, aber der Zeitpunkt ist nicht maßgebend. Diese Tasks laufen deshalb nur dann, wenn keiner der zeitgebundenen Tasks den Prozessor und andere konkurrierende Ressourcen braucht.
Implementierungsmöglichkeiten
Die gesamte Aufgabe wird in parallel laufende Tasks aufgeteilt. Einige laufen periodisch und andere aperiodisch durch. Die periodischen (zyklischen) Tasks führen eine Kontroll-Schleife mit den oben genannten 3 Phasen und müssen in ein gegebenes Zeitfenster passen. Die aperiodischen Tasks werden von asynchronen externen Interrupts (sporadischen Tasks) oder von internen Ereignissen (spontanen Tasks) aktiviert. Alle diese Tasks haben eine Initialisierungsfunktion, die einmal bei ihrer Erzeugung aufgerufen wird, und eine "handle"-Funktion,die bei jeder Aktivierung erneut aufgerufen wird. Die handle-Funktion muß ohne Verzögerungen durchlaufen und enden bevor sie wieder aufgerufen werden kann. Eine andere Sorte von Tasks (Ongoing Tasks) läuft in Hintergrund ohne Zeitanforderungen. Die ongoing Tasks können suspendiert und an derselben Stelle fortgesetzt werden, im Gegensatz zu den zeitgebundenen Tasks, die immer wieder an derselben Stelle (handle-Funktion) aktiviert werden.
Zeitgebundene Tasks
Periodische oder zyklische Tasks
Periodische Abläufe werden einmal pro Periode aktiviert und müssen vor dem Ende der Periode enden. Jeder Task hat seine eigene Periode, die Perioden von verschiedenen Tasks dürfen unterschiedlich sein. Die Perioden können auch dynamisch variieren, je nach Bedarf oder nach Prozessor-Belastung. Bei den zeitkritischen Tasks muß das Reaktionszeitfenster genau getroffen werden. Bei zeitempfindlichen Tasks muß nur die Frequenz garantiert werden, Zeitverschiebungen (jitter) innerhalb der Periode werden toleriert. Die periodischen Tasks werden am meisten bei Regelungsaufgaben eingesetzt. In der Regel laufen alle periodischen Tasks von Anfang an bis zum Ende der gesamtem Aufgabe. Es ist aber auch möglich, neue periodische Tasks mittendrin dynamisch zu erzeugen oder welche zu beenden.
Beispiele von periodischen Tasks sind Geschwindigkeitsregelung, Temperaturregelung, Servomechanismen.
Es gibt (Steuerungs-) Aufgaben, die periodisch aufgerufen werden sollen, aber nicht so gut in ein periodisches Schema passen. Beispiele davon sind komplexe Aufgaben, die aus einer Kette von Schritten bestehen. Ein beliebter Trick ist, daraus einen periodischen Task mit Statecharts zu machen. Das Vorgehen wird in "states" (Zustände) aufgeteilt und eine Variable sagt, in welchem Zustand sich die Steuerung befindet. Bei jeder Aktivierung des periodischen Tasks macht dessen handle-Funktion einen von der state-Variable abhängigen Sprung zum passenden Code und bevor die handle-Funktion endet, setzt sie die state-Variable auf das nächste state.
Aperiodische sporadische Tasks
Sie behandeln unregelmäßige externe Ereignisse (Interrupts). Meistens werden die sporadischen Tasks so schnell wie möglich (je nach Priorität) aktiviert und haben nur eine Deadline, im Gegensatz zu einem Reaktionszeitfenster. Man weiß nicht im voraus, wann die Interrupts eintreten werden, man kann aber eine obere Interruptfrequenzabschätzung machen, um genügend Zeit beim Scheduler im voraus zu reservieren. Oft reagieren diese Tasks auf (gefährliche) Ausnahmen und brauchen deswegen eine hohe Priorität.
Beispiele für sporadischen Tasks sind die Reaktion auf Interrupts wegen zu hoher Temperatur, zu hohem oder gefährlichem Druck oder einfach ein Mouse-click.
Aperiodische spontane Tasks
In Normalfall werden diese Tasks von anderen internen Aktivitäten (Tasks) irgendwann mittendrin in der gesamten Aufgabe erzeugt und für einen späteren Zeitpunkt in den Scheduler einprogrammiert. Dadurch erhalten sie ein definiertes Zeitfenster.
Beispiele für spontane Tasks mit Zeitfenster sind das Setzen von Timeouts und Alarm. z.B. wird ein Motor gestartet und in 10 Sekunden soll er eine bestimmte Position erreicht haben. Dann wird ein Task in 10 Sekunden aktiviert um zu prüfen, ob der Motor wie erwartet funktioniert.
Im Ausnahmenfall (Fehlererkennung) können auch spontane Tasks erzeugt werden, damit sie eine Fehlerbehandlung durchführen. In diesem Fall werden sie nicht für einen späteren Zeitpunkt einprogrammiert sondern sofort ausgeführt und erben dann die Deadline der Tasks, die die Ausnahme verursacht haben.
Beispiele für spontane Tasks als Ausnahmebehandlung sind Berechnungsfehler, ein Timeout, ein Alarm, ein Pointerfehler.
Spontane Tasks können auch erzeugt werden, um erwartete interne Ereignisse zu behandeln, z.B. das Eintreten einer Kommunikationsbotschaft und für Ressourcen- Verhandlungen.
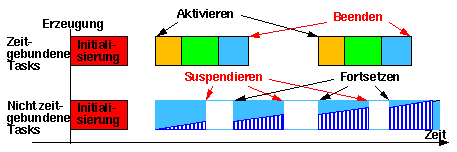
Nicht Zeitgebundene Tasks
Ongoing Tasks
Diese Tasks führen Berechnungen durch, die keine Zeitrestriktionen haben. Sie laufen in der Regel im Hintergrund mit einer niedrigen Priorität. Diese Tasks stellen keine handle-Funktion, die vom Scheduler aufgerufen wird, zur Verfügung, sondern sie werden einmal gestartet und dürfen laufen, so lange es nötig ist. Sie werden aber mittendrin unterbrochen, damit andere Tasks (z.B. die zeitgebundenen) arbeiten können, wenn sie den Prozessor brauchen. Nachdem alle zeitgebundenen Tasks befriedigt sind und auf spätere Reaktivierung warten, werden die Ongoing Tasks an der Stelle, wo sie geblieben sind fortgesetzt. So wird die ansonsten Idle-Zeit des Prozessors nützlich benutzt.
Viele Laufzeitsysteme sind nicht in der Lage, Tasks zwangsläufig zu unterbrechen. In diesen Fällen müssen die Ongoing Tasks freiwillig die Kontrolle abgeben (yield, wait, sleep), damit andere Tasks arbeiten können (eine Gefahrenquelle). Im Gegensatz zu den zeitgebundenen Tasks werden diese nicht innerhalb eines Zeitintervalls abgeschlossen.
Beispiele von Ongoing Tasks sind Optimierungsverfahren, um die laufende Steuerungsaufgabe zu verbessern.
Ongoing Tasks können auch zeitgebundene Aktivitäten durchführen. Viele komplexe Steuerungsaufgaben, die als ein periodischer Task mit Statecharts implementiert werden, können besser mit ongoing Tasks implementiert werden, denn die ongoing Tasks werden an der Stelle, wo sie suspendiert wurden, fortgesetzt. Sonst muß eine lange Aufgabe in kleine Perioden aufgeteilt werden (unnötige Arbeit und eine Gefahrenquelle). Falls ein ongoing Task zeitgebundene Aufgaben ausführt, muß er selbst für sein Timing sorgen, denn der Scheduler hat keinen Einfluß auf seine internen Aktivitäten. Dies kann erfolgen, indem der Task auf Interrupts oder auf das passende Zeitfenster wartet und mit seiner Priorität spielt.
Scheduling (Zuteilung des Prozessors)
Der Echtzeit-Scheduler muß dafür sorgen, daß jeder Task rechtzeitig aktiviert (zugeteilt) wird, damit er sein Reaktionszeitfenster trifft. Um dies zu garantieren, ist eine Ausführungszeit-Abschätzung der Tasks nötig. Wenn bekannt ist, wie lange jeder Task braucht und wo jedes Reaktionszeitfenster liegt, kann festgestellt werden, wann jeder Task aktiviert werden soll und im voraus kann analysiert werden, ob das System überhaupt realisierbar ist. Folgende Regeln müssen eingehalten werden:
- 1) Alle zeitkritischen Tasks müssen so zuteilbar sein, daß auch mit einer Worst-Case Ausführungszeit und mit der höchsten erwarteten Interruptsrate jedes Reaktionszeitfenster getroffen wird.
- 2) Alle zeitempfindlichen Tasks müssen so zuteilbar sein, daß mit der mittleren Ausführungszeit und mittleren Interruptsrate jedes Reaktionszeitfenster getroffen werden kann.
- 3) Es muß genügend Prozessor-Zeit frei bleiben, so daß die aperiodischen spontanen Tasks dynamisch zuteilbar sind, mit Worst-Case oder mit mittlerer Ausführungszeit und Frequenz.
- 4) Das Timing von zeitkritischen Tasks darf nicht von den anderen Tasks beeinflußt werden.
Für diese Analyse sind folgenden Daten nötig:
- Worst-Case Ausführungszeit der handle-Funktion aller zeitkritischen Tasks,
- Mittlere Ausführungszeit der handle-Funktion aller zeitempfindliche Tasks,
- Frequenz (oder Periode) der periodischen Tasks
- Höchstmögliche und mittlere Interruptsrate
- Höchstmögliche und mittlere Auftrittsrate der spontanen Tasks
- Zeitaufwand vom Scheduler selbst und vom Task-Wechseln
Je mehr man über das Laufzeitverhalten des Systems weiß, um so sicherer kann der Scheduler gemacht werden und sogar die Zeit-Slots für die aperiodischen zeitkritischen Tasks können im voraus reserviert werden. Aber meistens ist eine Zeitreservierung für alle aperiodischen Tasks nicht möglich, nur wenn der Prozessor eine sehr niedrige Belastung hat.
Darüber hinaus muß auch genügend Prozessor-Zeit frei bleiben, so daß die ongoing Tasks laufen können, besonders wenn sie zeitgebundene Aufgaben im Verborgenen durchführen. In diesem Fall muß eine Analyse gemacht werden, wieviel Ausführungszeit diese Tasks pro Zeiteinheit (z.B. Sekunde oder "major-Cycle") brauchen, um diese Zeit frei zu lassen. Dies ist das höchste was der Scheduler für die Ongoing Tasks garantieren kann. Für das Einhalten ihrer Timing-Anforderungen müssen sie selbst mit Delays und Prioritäten sorgen.
Wenn alle oben genannten Analysen beendet und alle Daten bekannt sind, dann kann man einen Scheduler (Zuteilungsprogramm), der die Timing-Anforderungen garantiert, fest programmieren (ein statischer Scheduler). Wenn es nicht möglich ist, von Anfang an alle Tasks und ihr Verhalten zu kennen, muß ein dynamischer Scheduler angewendet werden, bei dem zur Laufzeit die Tasks angemeldet werden. Der Scheduler versucht dann die dynamischen Timings-Anforderungen zu erfüllen, aber nur sehr wenig kann garantiert werden.
Statischer Scheduler
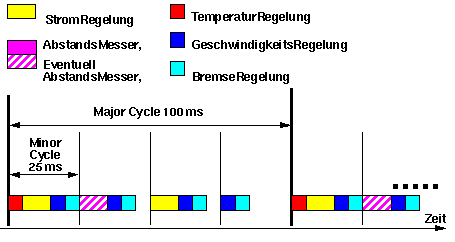
Das Zuteilungsprogramm wird vom Programmierer gemacht und es wird während der Laufzeit nicht geändert. Der Programmierer muß alle Tasks und ihre Zeit-Charakteristiken kennen. Dies geht gut bei den periodischen Tasks. Bei den aperiodischen Tasks muß man überall dort freie Zeit-Slots lassen, wo diese Tasks eintreten könnten. Dies ergibt eine schlechte Prozessor-Auslastung.
Die Methode besteht darin, zuerst eine übergeordnete Periode (Major-Cycle) zu finden, die das kleinste gemeinsame Vielfache von allen Perioden der Tasks ist. In diesem Major-Cycle werden alle periodischen Tasks mindestens einmal aufgerufen.
Die Vorteile dieses Schedulers sind:
-
Man weiß genau, was in der Laufzeit des Systems passiert:
-> höhere Sicherheit
-> Deterministisch
-> Man kann die Zeitfenster garantieren -
Der Scheduler ist einfach
-> höhere Sicherheit
-> Kann schnell programmiert und getestet werden - Der Laufzeit-Aufwand des Schedulers ist minimal
- Wen man nur periodische Tasks hat, kann man die höchstmögliche Prozessor-Auslastung erreichen und trotzdem die Zeitfenster garantieren.
-
Aperiodische Tasks sind ein Problem
-> Wenn man ihren Zeitfenster garantiert, hat man eine niedrige Prozessor-Auslastung - Es kann sich nicht an neue Bedingungen während der Laufzeit anpassen
- Alle Tasks-Zeitcharakteristiken müssen im voraus bekannt sein
- Tasks mit (relativ) langen Perioden verursachen ein großes Major-Cycle und vergrößern damit das Zuteilungsprogramm

Dynamischer Scheduler
Wenn der Scheduler nicht nur für eine Applikation sein soll, oder die Tasks entstehen und terminieren während der Laufzeit, oder wenn die Laufzeit-Charakteristiken der Tasks nicht im voraus ermittelbar sind, dann muß man den Weg mit einem dynamischen Scheduler wagen. Beim dynamischen Scheduling sind die Tasks nicht vorprogrammiert, sondern sie werden während der Laufzeit an- und abgemeldet. Der Scheduler versucht dann die Tasks so zu aktivieren, daß sie ihre Zeitfenster treffen, aber er kann nur wenig garantieren. Dieser Scheduler empfiehlt sich nicht für zeitkritische Tasks bei einer hohen Prozessor-Belastung (Erfahrungswert, nur unter 69%).
Preemptiv und nicht Preemptiv
Die preemptiven Betriebssysteme und/oder Laufzeitsysteme können Tasks ohne ihre aktive Beteiligung unterbrechen um andere fortzusetzen oder zu aktivieren, um eingetroffene Ereignisse (Zeitereignisse oder externe Ereignisse) zu behandeln.
Die nicht preemptiven Laufzeitsysteme sind darauf angewiesen, daß jeder Task den Prozessor freiwillig freigibt, z.B. sollen ongoing Tasks eine yield-Funktion oder eine delay-Funktion (sleep) aufrufen, um den Prozessor freizugeben, und die handle-Funktion jedes zeitgebundenen Tasks muß enden, bevor der Scheduler die handle-Funktion eines anderen Tasks aufrufen kann.
Die preemptiven Systeme sind aufwendiger zu implementieren, aber man hat die Sicherheit, daß keine unkooperativen Tasks andere Tasks blockieren können und außerdem kann das System schneller auf (externe und Zeit-) Ereignisse reagieren. Ihr großer Nachteil ist der Undeterminismus bei der Ausführung der Tasks. Der Programmierer muß sehr aufpassen und atomare Blöcke definieren, weil der Scheduler sonst jeden Task an beliebigen Stellen unterbrechen kann, um andere Tasks fortzusetzen. Das kann unerwartete Nebenwirkungen haben. Das Testen des Systems wird auch komplexer, z.B. liefert ein sequentielles Programm bei gleichen Inputs dieselben Outputs in identischen Reihenfolge. Wenn die Aufgabe in 5 nicht preemptive Tasks aufgeteilt wird, dann hat man 120 mögliche Permutationen für die Outputs. Dies zu bewerten ist schon etwas schwieriger. Aber mit 5 preemptiven Tasks hat man vielleicht einige Millionen von richtigen Permutationen für die Outputs, und wenn man noch das Timing-Verhalten berücksichtigt, dann hat man ein System, das nicht jeder testen kann.
Für sicherheitsrelevante eingebettete Systeme würde ich lieber für ein nicht preemptives System plädieren. Bei eingebetteten Systemen kennt man im voraus alle Tasks, die darauf laufen sollen, und alle Tasks laufen Hand in Hand. Das Versagen von einem Task kann das Versagen des gesamten Systems bedeuten, auch wenn die anderen Tasks noch lauffähig wären. Deswegen ist das Problem von unkooperativen Tasks hier nicht so schwerwiegend wie bei offenen Systemen, wo ein nicht preemptives Betriebssystem total ungeeignet wäre.
Bei sicherheitsrelevanten eingebetteten Systemen wird aus demselben Grund davon abgeraten, mit externen Interrupts zu arbeiten. Ein Interrupt soll nur zugelassen werden, wenn es eine gefährliche Ausnahme signalisiert. In diesem Fall muß eine Ausnahmebehandlung eingeleitet werden und die laufenden Tasks werden nicht unterbrochen sondern abgebrochen. Nach der Ausnahme-Behandlung wird ein Recovery durchgeführt und die normal laufenden Tasks werden wieder gestartet.
Prioritäten
Bei dynamischen Schedulern kann die Reihenfolge der Ausführung der Tasks durch Prioritäten beeinflußt werden. Aber für eine garantierte, genau vorgegebene Reihenfolge der Tasks muß ein statischer Scheduler benutzt werden. Prioritäten werden auch benutzt, um zu verhindern, daß unwichtige Aufgaben die Ausführung von wichtigeren Aufgaben verhindern.
Zeitgebundene Tasks sollen Ihre Priorität steigern je näher sie an Ihre Deadline kommen, besonders die zeitkritischen Tasks, bei denen das Verpassen der Zeitfenster einen Systemausfall bedeutet. Zeitempfindliche Tasks sollen eine niedrigere Priorität als die zeitkritischen Tasks haben, denn sie können Timing-Fehler tolerieren. Die ongoing Tasks ohne Zeitanforderungen können die niedrigste Priorität bekommen.
Die Prioritäten müssen nicht statisch sein, sie können sich folgendermaßen ändern:
Prioritätsanpassung
Je nach Situation können die Tasks ihre Priorität ändern. Z.B. bei einer Temperatur-Regelung, wenn die Temperatur sehr hoch ist, soll der Task, der die Kühlung regelt, eine hohe Priorität bekommen. Wenn die Temperatur sehr niedrig ist soll der Task, der die Heizung regelt, die höhere Priorität bekommen.
Prioritätsvererbung
Wenn ein Task A einen Service von einem Task B braucht (Remote Procedure Call) und A wird blockiert bis B antwortet, dann soll B mindestens dieselbe Priorität wie A haben, wenn nicht, dann soll B die Priorität von A erben bis der Service beendet ist.
Ausführungszeit: Analyse und Behandlung
Für statisches Scheduling und für manche schlauen dynamischen Scheduler muß man die Ausführungszeit der Tasks kennen. Die mittlere Ausführungszeit (für zeitempfindliche Tasks) wird mit Messungen festgestellt und ist deswegen relativ einfach zu ermitteln. Für die Ermittlung der Worst-Case (höchst mögliche) Ausführungszeit benötigt man Zeitmodelle für den Ziel-Rechner (Prozessor + Speicher + Cache +....), Netzanbindung und Betriebssystemdienste. Die Worst-Case Ausführungszeit eines Blocks (für zeitkritische Aufgaben) kann nur bestimmt werden, wenn alle seine Befehle eine obere Ausführungszeitsgrenze haben und er nur Schleifen mit festen bekannten Grenzen hat. Dies verbietet Polling auf Ereignisse, dynamische Speicher-Alloziierung (new xx) und benutzen von virtuellem Speicher. Alle benötigten Speicher-Bereiche sollen von Anfang an alloziiert und gelockt (für den virtuellen Speicher-Swapper) sein. Die zeitgebundenen Tasks mit engen Zeitanforderungen dürfen nicht ausgeswappt werden.
Um die höchstmögliche Ausführungszeit zu ermitteln, werden bei linearen, sequentiellen Segmenten die einzelnen Ausführungszeiten addiert. Bei Schleifen wird die Ausführungszeit des wiederholten Segments mit der maximalen Anzahl von Durchläufen multipliziert. Bei If-then-else und case Anweisungen wird die längste Ausführungszeit genommen.
Cache ist ein Vorteil für die mittlere Ausführungszeit (Leistungsverbesserung bis zu Faktor 20) aber ein Nachteil für die Worst-Case Ausführungszeit der Tasks. Bei der Worst-Case Berechnung muß man davon ausgehen daß die zugegriffenen Speicher-Adressen nicht im Cache sind (Cache-miss). So ein Zugriff dauert länger als einer ohne Cache. Deswegen verschlechtert ein Cache die Worst-Case Ausführungszeit der Tasks und verursacht eine sehr schlechte Prozessor-Ausnutzung bei zeitkritischen Aufgaben. Eine realistische Worst-Case Abschätzung, die die Cache-Dynamik richtig berücksichtigt, ist äußerst schwierig. Bei zeitkritischen Aufgaben werden deswegen Systeme ohne Cache vorgezogen oder die Speicherbereiche dieser Tasks müssen im Cache gelockt sein.
Pipeline und parallele Verarbeitung erschwert auch die Ermittlung der Worst-Case Ausführungszeit. Eine extreme Worst-Case Analyse (Pipeline immer leer und keine Parallelität) ist einfach aber ergibt ein sehr schlechtes Bild des Systems. Eine realistische Analyse ist äußerst schwierig, denn kleine Änderungen der Reihenfolge der Operationen können große Ausführungszeitunterschiede bringen. Daher werden oft CISC Prozessoren gegenüber RISC Prozessoren vorgezogen, weil sie einfacher zu modellieren sind. Die RISC-Prozessoren haben eine höhere interne Parallelität, welche die Modelle komplexer macht.
Neben der Ausführungszeit muß auch die Ausführungsfrequenz bekannt sein. Bei den periodischen Tasks ist das nur problematisch, wenn sie Ihre Periode dynamisch ändern. Bei den sporadischen Tasks kann man keine Worst-Case Frequenz angeben, nur Abschätzungen machen, wie hoch die oberste Grenze liegen kann. Oft ist der Unterschied zwischen mittlerer und höchster Frequenz der sporadischen Tasks so groß, daß man für zeitkritische Aufgaben nur eine sehr schlechte Prozessor-Auslastung erreichen kann.
Wie man sieht, sind die zeitkritischen Tasks ein unangenehmes Problem, die uns zu vielen Restriktionen zwingen. Um mehr Freiheit bei der Implementierung von zeitkritischen Tasks zu haben, muß man sie so konzipieren, daß sie Timing-Ausnahmen tolerieren können. In diesem Konzept wird ein zeitkritischer Task nicht im voraus vollständig analysiert, aber während der Laufzeit bekommt er eine begrenzte Zeit für seine Aufgabe. Wenn er nicht rechtzeitig fertig geworden ist, wird er abgebrochen und seine vorbereitete Ausnahmemaßnahme wird eingeleitet. Die Ausnahmemaßnahme ist aber eine zeitkritische Funktion, die im Reaktionszeitfenster ihre Ergebnisse liefern muß. Diese Ergebnisse werden nicht so genau und nicht so optimal wie die vom normalen Task sein, aber in jedem Fall besser als gar keine Reaktion (Imprecise-Computing), denn gar keine Reaktion bei zeitkrischen Aufgaben bedeutet ein Systemversagen.
Die handle-Funktion eines Imprecise-Computing-Tasks wird in drei Unterfunktionen aufgeteilt:
- Startup: ist eine zeitkritische Aufgabe und muß vollständig analysierbar sein.
- Work: ist nur eine zeitempfindliche Aufgabe, aber muß abbrechbar sein.
- Finalize: ähnlich wie bei startup.
Die startup-Funktion berechnet grob die Reaktion aber gibt sie nicht aus, sie speichert sie nur ab. Die work-Funktion macht eine genaue Berechnung und speichert sie ab. Sie muß am Ende noch ein Flag setzen, so daß die finalize-Funktion erkennen kann, ob die work-Funktion fertig geworden ist oder ob sie abgebrochen wurde. Das Laufzeitsystem setzt vor dem Starten der work-Funktion einen Time-out Alarm mit reichlich Zeit vor der Deadline, so daß die finalize-Funktion noch genügend Zeit hat, ihre Aufgabe im Reaktionszeitfenster auszuführen. Wenn das Time-out-Signal aktiviert wird, wird die work-Funktion zwangsläufig beendet. Nach dem Beenden der work-Funktion (freiwillig oder gezwungen) wird die finalize-Funktion aktiviert. Sie untersucht, wie weit die work-Funktion gekommen ist und nimmt die besten vorhandenen Ergebnisse und gibt als Reaktion aus.
Kurz die Realität
Bei vielen kleinen Entwicklungen (nicht bei der Autoindustrie) mit kleinen kompakten eingebetteten Systemen schreibt man in der Regel am Ende selbst seinen Scheduler und sein Laufzeitsystem. Bei größeren Systemen benutzt man oft irgendein kommerzielles Real-Time Betriebssystem, das als einzige Echtzeit-Unterstützung nur eine Delay-Funktion (z.B. sleep) zur Verfügung stellt. Zeitfenster werden nicht unterstützt, das einzige, was garantiert werden kann, ist, daß ein suspendierter Task nicht kürzer suspendiert wird, als beantragt. Es gibt auch viel schlauere Echtzeit-Betriebssysteme, die auch Zeitfenster unterstützen, aber sie werden zu selten benutzt. Eine Worst-Case Ausführungszeit-Analyse wird selten gemacht, und wenn doch, wird sie vom Scheduler nicht benutzt (mit wenigen Ausnahmen).
Java public-domain Software zum Experimentieren
Meine Arbeitsgruppe an der GMD-FIRST arbeitet an Echtzeit-Steuerungs- und Simulationssystemen. Zum Experimentieren haben wir einen Echtzeit dynamischen nicht preemptiven Scheduler in Java geschrieben. Er unterstützt periodische, sporadische und spontane Tasks (ohne Reaktionszeitfenster). Ongoing Tasks können als separate Java-Threads unabhängig von Scheduler laufen.
Die Software kann von der URL
./public_domain.html
geholt werden.
Ein abschliessender Kommentar
Als ich meinem Sohn einen Abchnitt des Textes vorgelesen habe, hat er mir ein Bild gemalt von dem, was er verstanden hat:
Weitere Referenzen
Mein Buch: Sichere und Fehlertolerante Steuerungen

Real Time Seminar an der TU-Berlin
./seminar/index.html
Entwicklung sicherheitsrelevanter eingebetteter Systeme, Real Time, Posix, Real Time java.
The IEEE-CS TC-RTS
http://cs-www.bu.edu/pub/ieee-rts
"The Real-Time Research repository" Software, Research Groups, Conferences, Courses, Tools, etc.
CHORUS/JaZZ
http://www.chorus.com/Products/Datasheets/jazz.html
CHORUS/JaZZ is a Java real-time operating system. It provides a natural platform for Java to interface to the embedded world.
Portos von Oberon microsystems
http://www.oberon.ch/portos/index.html
Portos is a light-weight deadline-driven real-time operating system (RTOS) for hard real-time applications. It is optimized for embedded high-performance applications.
PERCs from NewMonics Inc.
http://www.newmonics.com
PERC is a clean-room implementation of the Java programming language and run-time system. It's design has been tailored to meet the specialized needs of the embedded real-time and consumer electronics industries.
Real-Time Systmes and Programming Langauges,
Alan Burns & Andy Wellings. 1995
Real Time Programing Languages,Operating systems, scheduling, and Real Time Distributed Systems
Real Time Systems
Yann Hang Ledd & C.M. Krischna, 1993
Real time Architectures, Operating Systems, Performance Modeling.
Advances in Real Time Systems
Sang H. Son, 1995
Real Time Operating Systems, Communication, Scheduling and Resource management, Formal Methods, Programming Languages
Programming for the Real World -POSIX.4,
Bill O. Gallmeister, 1995.
Definition of a Real Time interface for RT-Operating Systems (e.g. Posix/Unix)