Fehlertoleranz gegen Entwicklungsfehler
GMD-FIRST (http://www.first.fhg.de)
3.1
Umgang mit Software- und anderen Entwicklungsfehlern
Die Entwicklungsfehler sind permanente Fehler, aber sie machen sich nur unerwartet bemerkbar (sonst würde man sie kennen und korrigieren können). Hier werden hauptsächlich die Software-Entwicklungsfehler (weil diese am häufigsten sind) angesprochen, aber viele der hier besprochenen Methoden können auch auf andere Komponenten angewandt werden. Man kann nicht von Softwareausfällen reden, da Software nicht altert und nicht kaputt geht. Ihre Fehler sind von Anfang an da (sie ist von Anfang an kaputt!). Z.B. die alltäglichen PC-Abstürze sind softwarebedingt. Hardware-Ausfälle sind sogar bei den extrem billigen PCs sehr selten. Ein PC aus dem Supermarkt kann mehrere Jahre ohne Hardwarefehler laufen. Für dessen Software bleibt das ein Traum. Dies soll nicht bedeuten, daß nur die Software Entwicklungsfehler haben kann. Alle komplexen Komponenten werden auch welche haben. Es wird akzeptiert, daß man keine fehlerfreie komplexe Software schreiben kann [formale Methoden]. Es wird aber geglaubt, daß man doch fehlerfreie und absolut fehlertolerante Hardware bauen kann. Wenn das der Fall wäre, könnte man die gesamte Funktionalität in Hardware implementieren und damit wäre das System 100% fehlerfrei.
Kritische aber nicht fehlertolerante Systeme Fehlertolerante Systeme
Hardware 50% 8% Software 25% 65% Umgebung & Komm. 15% 7% Bedienung 10% 10%
Der Kampf gegen Fehler wird in drei Schritte unterteilt:
1) Fehlerprävention
Als erste Maßnahme sollen Fehler vermieden werden (Fehlerprävention). In erster Reihe empfiehlt sich, alles so einfach wie möglich zu machen, z.B. einfache Applikationen, einfaches Betriebssystem usw. Es lohnt sich vielfach, das System ein zweites Mal zu überlegen, um es zu vereinfachen [Konzeption]. In der Entwicklung können auch mathematische Methoden [formale Methoden], andere Softwareengineering-Techniken benutzt werden. Menschliche Fehler sind repetitiv, ihre Muster wiederholen sich immer wieder. Deswegen ist es eine Hilfe, Ihre eigenen Fehler zu protokollieren und zu klassifizieren. Dann können Sie bei neuen Entwicklungen nach Ihrem eigenen Fehlermuster suchen und dadurch eine Fehlerwiederholung vermeiden und mehr als 50% der Entwicklungsfehler frühzeitig korrigieren.
Eine ähnliche Wirkung kann man durch fremde Inspektionen (Audits) erreichen. Allein durch die Vorstellung, daß Sie Ihren Code jemandem zeigen und erklären müssen, werden Sie viel ordentlicher und aufmerksamer entwickeln. Bei der Erklärung Ihres Codes werden Sie selbst Details (und eventuell Fehler) erkennen, die Ihnen beim Programmieren nicht gegenwärtig waren. Hier finden Sie eine Liste von positiven Erfahrungen durch Inspektionen:
IBM 1975: Inspektionen der Spezifikation, Design und Implementierung reduzierte bis 95% der Testzeit.
Imperial Chemical Industries 1982: Die Wartungszeit bei inspiziertem Code war 0,6 Minuten/Zeile/Jahr, und 7 Minuten/Zeile/Jahr bei nicht inspiziertem Code.
ICL 1986: Der Aufwand, um Fehler durch Tests zu finden war 8,5 Personen-Stunden pro Fehler, durch Inspektion nur 1,6 Personen-Stunde pro Fehler.
Stratus Conimuum Languages 1995: Die Inspektionsaufwand betrug 10% des Projektaufwands, der Testaufwand war 50% und 64% der Fehler wurden durch Inspektion gefunden.
2) Tests
Aber trotz all dieser Methoden werden immer Fehler übrig bleiben. Die zweite Maßnahme ist, Fehler zu finden und korrigieren (Tests). Einfache Systeme können systematisch fast vollständig getestet werden. Komplexe Systeme (z.B. Softwareanteile) können nicht vollständig getestet werden und die Anzahl der unentdeckten Entwicklungsfehler wächst sogar exponentiell mit der Komplexität des Systems. Alle übrigen unentdeckten Fehler stellen eine latente Gefahr dar. Meistens wird nur die Funktionalität des Systems (teilweise) getestet und der gesamte Fehlertoleranz-Teil dabei vergessen. Z.B. ist die Aufwandsverteilung bei der Telekommunikation 50% LOC bei der Kernfunktionalität und 50% LOC bei der Fehlerbehandlung, dagegen wird beim Testen der Fehlerbehandlung weniger als 10% des gesamten Testaufwands gewidmet. Fehlererkennung und Recovery-Mechanismen sind so wichtig wie die restliche Funktionalität, aber sie werden häufig unterschätzt und deswegen vernachlässigt: Sie werden als letztes entwickelt und als letztes und am wenigsten getestet, dabei ist dieser Test der schwierigste. Das System muß dafür in extreme Streß-Situationen gebracht werden, und die Fehler-Injektion, ohne das bestehende System zu modifizieren, ist sehr schwierig. Doch sollten Sie diesen Aufwand nicht übersehen oder scheuen.
3) Fehlerbehandlung
Als dritte Maßnahme soll das System vorbereitet werden, Fehler während des Betriebs zu erkennen, zu behandeln und zu melden, damit sie korrigiert werden können.
Es macht keinen Sinn Replikations-Fehlertoleranzmechanismen gegen Software- und Entwicklungsfehler einzusetzen. Eine Replikation der Komponenten repliziert auch die Fehler und bringt nur noch neue potentielle Fehler dazu. Der Umgang mit Entwicklungsfehlern ist schwieriger als der mit (erwarteten) Ausfällen, weil es sich hierbei um unbekannte Probleme handelt. Die (Software-) Steuerung muß nicht nur Fehler der anderen Komponenten behandeln können, sondern auch die eigenen - und das ist das schwierigste, denn wer sieht die eigenen Fehler? Noch schlimmer ist die Vorstellung, daß die meist unkreative und dumme Steuerung ganz alleine mit unbekannten Zuständen, die nicht einmal ihr Schöpfer (Ingenieur) kannte, zurechtkommen soll. Man kann kaum im voraus Handlungen vorbereiten, wenn man nicht weiß, was passieren wird. Deswegen sind diese Fehler eine der größten Quellen von Katastrophen.
Fehlertoleranz gegen die übriggebliebene Entwicklungsfehler
Hier werden drei Techniken als Maßnahme gegen Entwicklungsfehler erwähnt. 1. Die Konstruktion von robusten Software-Modulen, die ihre Ergebnisse selbst streng prüfen, bevor sie sie liefern. Dies ist die einfachste Alternative, bietet aber keinen Schutz gegen Konzeptionsfehler. 2. Die Konstruktion eines Monitormoduls, das die Ergebnisse des Arbeitermoduls überprüft (Extern-Tests). Um Konzeptionsfehler zu erkennen, soll der Monitor von einem getrennten Team entwickelt werden. 3. Eine diversitäre Entwicklung, wo die kritischen Module mehrfach von verschiedenen Teams unabhängig voneinander entwickelt werden.
Es ist sehr wichtig aufzupassen, daß die Prüfungen in den robusten Modulen und die vom externen Monitor weder die Ergebnisse noch den Verlauf der Berechnungen beeinträchtigen. Sie dürfen keine Nebenwirkungen haben. Man muß beobachten ohne zu beeinflussen. Beim Echtzeitverhalten des Systems wird das kaum möglich sein. Deswegen sollen alle Prüfungen zuerst eingebaut werden und danach wird das Echtzeitverhalten analysiert.
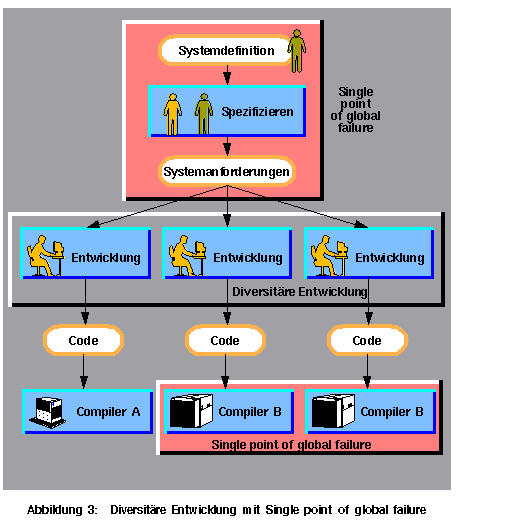
Keine dieser Techniken garantiert eine vollständige Sicherheit, besonderes nicht, wenn es einen "Single point of global failure" bei der Entwicklung gibt (s. Beispiel in Abbildung 3). Fehler aus der Anforderungsspezifikation werden in allen Versionen vorhanden sein. Außerdem helfen diese Techniken nur, Fehler während der Laufzeit zu erkennen, aber nicht, sie zu korrigieren. Dadurch wird mindestens das weitere Verbreiten des Fehlers und eventuell sogar ein Systemausfall verhindert. Mit einer dreifachen diversitären Entwicklung, was sehr selten und teuer ist, kann eventuell ein Entwicklungsfehler ausmaskiert werden, um Fehlertoleranz auch gegen Entwicklungsfehler anzubieten. Ohne eine vollständige Fehlertoleranz gegen Entwicklungsfehler ist es sehr schwierig, den normalen Betrieb aufrechtzuerhalten, nachdem sich ein Entwicklungsfehler bemerkbar gemacht hat, denn das System gerät in unvorhersehbare Zustände. Es ist hilfreich, wenn ein Operator da ist, an den das System sich wenden kann. Wenn nicht, oder wenn das System zu schnell für eine menschliche Handlung läuft, soll das System in einen sicheren Zustand übergehen (Fail safe) und ein Recovery durchführen.
1. Robuste Software durch interne Prüfungen
Die robusten Software-Module sollen mögliche Bedienungsfehler sowie eigene Fehler abfangen (robuste, defensive Programmierung). Wichtig dabei sind die Signale (Software Interrupts) aus dem Betriebssystem. Dadurch signalisiert das Betriebssystem, daß es einen Fehler bei der Programmausführung erkannt hat, den das Programm selbst nicht bemerkt hat, z.B. Adressraumverletzungen oder Division durch Null. Wenn das Programm diese Signale nicht abfängt, wird es vom Betriebssystem abgebrochen. Dies ist ziemlich das schlimmste, was passieren kann, denn das System bleibt ohne Steuerung. Die Software soll unabhängig von Inputs, Rechnerbelastung oder Zustand richtig arbeiten. Sie darf durch ihre Tätigkeit oder Untätigkeit nicht die Ursache eines Systemfehlers sein.
Bei den sicherheitskritischen Anwendungen geschehen die meisten Ausfälle durch Schnittstellenfehler. Um sich dagegen zu schützen, müssen Sie davon ausgehen, daß 1. Ihre Funktion mit falschen Parametern aufgerufen wird, 2. Ihre Fehlermeldungen ignoriert werden, und 3. die Funktionen, die Sie aufrufen, Fehler produzieren werden. Es ist empfehlenswert, 1. Strong Prototyping der Funktionen zu benutzen (z.B. Java, C++). Dokumentieren Sie mit Beispielen die Benutzung Ihrer Funktionen, so daß man die Beispiele mit Cut-and-Paste in die Applikation kopieren kann. 2. Machen Sie es schwierig, Ihre Fehlermeldungen zu ignorieren, z.B. nicht einfach als ein Return-Wert. (Throw & Catch von Java und einige c++ Dialekte). 3. Ignorieren Sie nicht die möglichen Fehlermeldungen von den untergeordneten Modulen.
Man sollte intern in den Modulen Prüfungen durchführen für: 1. Annahmen und Erwartungen, 2. die Integrität der abgespeicherten und der übertragenen Daten; 3. die Korrektheit oder Plausibilität der Datentransformationen (Berechnungen, Input/Output).
1.1 Prüfung der Annahmen und Erwartungen
Design-Angaben, Vorgaben, Annahmen u.a. können durch Assertions getestet werden. Sie können zu 3 verschiedenen Zeitpunkten benutzt werden:
Zur Compile-Zeit: Durch den Präprozessor (nur c oder c++) können konstante Daten geprüft werden, so daß bei der Mißachtung von Design-Angaben oder Erwartungen gleich beim Kompilieren Fehler erkannt werden können, z.B.
Fehler size zu klein // dies ist ein Compilerfehler (kein c Syntax)
Zur Debug-Zeit: Hier können komplexere Annahmen, die über Konstanten hinausgehen, geprüft werden. Aber sind die Annahmen bestätigt, brauchen sie nicht mehr während der Laufzeit des Systems geprüft zu werden und die Assertions können dann entfernt werden. Deswegen dürften sie keine Nebenwirkungen haben. Leider können Nebenwirkungen auf das Zeitverhalten nicht vermieden werden. Deshalb darf man bei zeitkritischen Aufgaben diese Assertions nach dem Zeitverhaltenstest nicht mehr entfernen. Hier ein Beispiel für Debug-Zeit-Assertions:
Assert(x >= 0 , "SQRT Fehler");
Zur Laufzeit: Hier können Fehler während der Operation des Systems erkannt werden. Dies sind die Fehler, die man nicht ausschließen kann und deswegen werden diese Assertions-Prüfungen nicht entfernt.
1.2. Prüfung der Integrität der Daten und des Programms
Es muß garantiert werden, daß die Benutzerdaten im Speicher korrekt sind. Daten können random gestört werden (Speicherfehler) oder systematisch durch Programmfehler (Pointerfehler). Random-Fehler können durch Parity Checks und EDC (Error Detection and Correction) Kodierungen per Hardware leicht erkannt und behandelt werden. Einige sehr grobe systematische Fehler können durch eine Hardware-MMU (Memory Management Unit) oder durch Adressraumschutzregister erkannt werden, die meisten aber nicht und Parity-Check bietet dagegen auch keinen Schutz. Für eine sicherere Erkennung können Speicherblöcke, wie z.B. große Objekte, durch einen CRC (Cyclic Redundancy Code) oder mit einer Checksum gesichert werden. Bei jeder Änderung eines Attributes eines Objektes wird erneut die objektspezifische Checksum aktualisiert. Eine unerwünschte Veränderung der Daten würde dies nicht tun. Vor jedem kritischen Zugriff eines Objekts wird die Checksum geprüft. Dies ist sehr zeitaufwendig, aber so kann man die Integrität der Objektdaten garantieren. Wenn ein Teil eines Objekts ungewollt gestört wird, wird der nächste normale Zugriff des Objekts dies erkennen, denn die Wahrscheinlichkeit, daß ein Fehler noch die Checksum richtig aktualisiert, ist extrem niedrig.
Eine schnellere, aber speicherintensivere Alternative ist, alle wichtigen Daten zweimal in völlig verschiedene Speicherbereiche zu schreiben. Bei jedem Lesezugriff werden beide Kopien verglichen. Der Adressenabstand zwischen beiden Kopien darf keine Systemkonstante sein, sondern muß objektspezifisch sein. Ist das nicht der Fall, kann ein Pointerfehler beide Kopien gleichmäßig verändern, und der Fehler bleibt dann unerkannt.
Die Konsistenz, Integrität und richtige Anwendung von Objekten können durch folgende Maßnahmen geprüft werden: 1. Jede Struktur wird mit einem Attribut (Variable) erweitert, um ihren eigenen Typ zu identifizieren. Dieses Attribut soll beim Konstruktor des Objekts initialisiert werden und dabei versuchen, Bitmuster zu benutzen, die nur schwer per Zufall wiederholt werden können, z.B. nicht 0 oder 1 oder 1xffff usw. Dieses Muster soll typspezifisch sein und darf sich bei anderen Typen nicht wiederholen. Jeder Zugriff auf ein Objekt prüft als erstes seinen Typ. 2. Noch ein Attribut identifiziert den Zustand des Objekts, z.B. initialisiert, gelöscht, blockiert, usw. Hierfür sollen wiederum keine typischen Werte wie 1, 0, 0xfff usw. benutzt werden. Jede Operation auf einem Objekt soll prüfen, ob das Objekt im erwarteten Zustand ist. 3. Ein Attribut identifiziert die Version des Objekts. Die Version soll bei jeder Änderung inkrementiert werden. 4. Ein Attribut soll den Erzeuger des Objekts (z.B. User-ID oder Objekt-Ref.) identifizieren. So kann geprüft werden, ob das Objekt von der erwarteten Stelle stammt. Alle diese Attribute werden auf 0 gesetzt, wenn das Objekt gelöscht (deleted) wird. Dadurch kann erkannt werden, ob Programmteile auf veraltete Daten zugreifen.
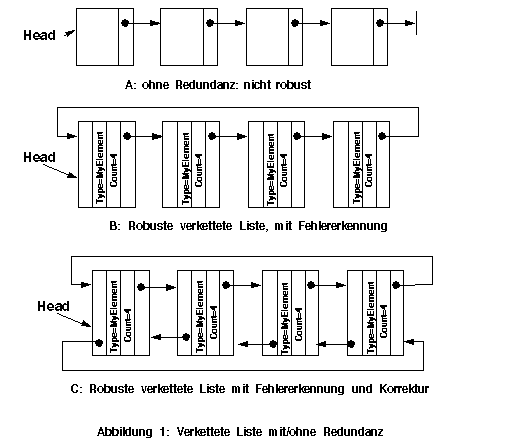
Rekursive Datenstrukturen können durch zusätzliche Redundanz geschützt werden. Die Abbildung 1 zeigt ein Beispiel anhand einer verketteten Liste. Ein Pointerfehler bei der Liste ohne Redundanz (A) kann nur nach einer gravierenden Speicherschutzvetletzung erkannt werden. Die Redundanz der Liste B erlaubt zu erkennung, ob man an der falschen Stelle gelandet ist (Pointerfehler), bietet aber keine Hilfe, um den Fehler zu korrigieren. Bei Liste C kann ein Fehler erkannt und korrigiert werden.
Bei den Nachrichtenübertragung können Random-Fehler durch CRC und Cheksums erkannt werden, systematische Fehler aber nicht. Einige solcher Fehler können durch die Verwendung von Authentifizierung (Kryptologie) des Senders, durch Nachrichten-Zähler und Kontext-Informationen erkannt werden. Die Richtigkeit der empfangenen Daten soll mit den gleichen Techniken für die Prüfung der Datentransformationen weiter getestet werden.
Der Programmcode kann auch beschädigt werden (zusätzlich zu den Fehlern, die er sowieso in sich hat). Dies kann durch regelmäßige Prüfungen auf Checksums oder CRC-Codes für Programmcodemodule erkannt werden. Der Kontrollfluß des Programms soll auch auf Störungen geprüft werden. Dies kann wie im folgenden Beispiel erfolgen:
IF (Block-B) THEN Block-C ELSE Block-D
Block-B: { if(pos != a) FlowError(); ...... pos = b;}
Block-C: { if(pos != b) FlowError(); ...... pos = c;}
Block-D: { if(pos != b) FlowError(); ...... pos = d;}
Block-E: { if(pos != c && pos != d) FlowError(); ...... pos = e;}
Die Blockposition wird am Anfangs des Blocks geprüft und am Ende aktualisiert. Dadurch kann erkannt werden, ob ein Block frühzeitig beendet wurde. Um zu prüfen, ob ein Block mittendrin angefangen wurde, kann eine extra Variable benutzt werden, die am Anfang des Block gesetzt wird.
Diese Kontrolle kann durch den Compiler oder durch einen Präprozessor generiert werden [Wildner], so daß es keinen extra Programmierungsaufwand bedeutet. Für große Blöcke ist der Laufzeitaufwand relativ niedrig, aber bei kleinen Blöcken kann er enorm werden.
1.3. Prüfung der Datentransformationen
Komplexe (und deswegen unsichere) Datentransformationen, wie z.B. Berechnungen, Input/Output, aber auch die empfangenen Daten aus anderen Modulen sollen gegen die bekannten Eigenschaften der Daten geprüft werden (Plausibilitätsprüfungen). Dafür kann man z.B. die physikalischen Grenzen der Daten benutzen oder die Tatsache, daß Zeitstempel und Nachrichtenzähler nicht zurücklaufen dürfen. Meistens hat man eine grobe Erwartung der Ergebnisse. Dies kann auch in der Plausibilitätsprüfung benutzt werden.
Mittendrin in den Berechnungen können "Asserts" benutzt werden. Dabei werden auch die a priori bekannten Eigenschaften der Berechnung benutzt. Z.B. kann beim Durchgehen einer sortierten Liste geprüft werden, ob der zuletzt gelesene Wert tatsächlich größer als der vorherige ist.
Es gibt auch komplexe Berechnungen, deren Ergebnisse einfach zu überprüfen sind. Einige Berechnungen sind komplex in eine Richtung aber einfach in der Gegenrichtung. Die Ergebnisse können dann durch einen Umkehrtest (reverse computing) geprüft werden. Ein einfaches Beispiel ist die Berechnung der Quadratwurzel. Die Funktion dafür besteht aus ca. 100 Zeilen C, das Ergebnis kann aber mit einer einzigen Multiplikation geprüft werden. z.B.
if(a*a != b) /* Vorsicht mit Approximations - und Rundungsfehler! */
Einige Berechnungen haben Randbedingungen, wie z.B. Sicherheitsanforderungen. Es ist sinnvoll, die Sicherheitsanforderungen von dem Rest der Spezifikation zu trennen und sie als Prüfungsvorgabe zu benutzen. Z.B. kann ein Roboterarm einen verbotenen Bereich haben (Kollisionsgefahr), nach jeder Bewegungsberechnung kann geprüft werden, ob die Sollwerte den Arm in den verbotenen Bereich bringen würden.
Berechnungen (oder Operationen) können durch Vorbedingungen (preconditions) geschützt werden. Die Vorbedingungen müssen stimmen, bevor die Berechnung anfangen kann. Beispielsweise die Wurzelberechnung hat als Vorbedingung, daß der Parameter positiv ist, eine POP-Operation (Lesen aus einem Stack) hat die Vorbedingung, daß der Stack nicht leer sein darf. Nach der Operation kann man auch Nachbedingungen (postconditions) prüfen. Z.B. darf der Stack nach der POP-Operation nicht voll sein (wenn man etwas wegnimmt, muß mindestens ein Platz frei bleiben). Einige Programmiersprachen (z.B. Eiffel) unterstützen direkt diese Konstrukte und bieten sogar alternative Blocks, wenn etwas nicht stimmt, z.B.:
ensure a>b by {....} else by {....} else by {....} else Error;
Alle diese Prüfungen beziehen sich nur auf komplexe Operationen. Eine Prüfung jeder elementaren Operation würde das Programm unnütz machen.
2. Monitor: Externe Prüfung, vertrauenswürdige Module
Das Arbeitermodul führt komplexe Berechnungen für die Steuerung durch. Seine Aktionen, Ergebnisse und Befehle können von außen durch ein Monitormodul beobachtet und geprüft werden. Die Vorteile dabei sind 1.: Arbeiter und Monitor können von verschiedenen Teams entwickelt werden, dadurch können einige Denkfehler entdeckt werden (dasselbe Prinzip der diversitären Entwicklung). 2.: Arbeiter und Monitor können in verschiedenen Prozessoren oder Knotenrechnern laufen. Dadurch wird der Monitor vor schwerwiegenden Fehlern des Arbeiters (z.B. er hängt sich auf oder überschreibt fremde Adressbereiche) geschützt. 3.: Der externe Monitor kann Timingfehler (zu spät oder zu früh) abfangen. Dazu zählt auch, wenn der Arbeiter nicht mehr reagiert.
Der Monitor kann auch den Kontrollfluß des Arbeiters verfolgen (mit Hilfe des Arbeiters selbst), um feststellen zu können, ob alles normal läuft. Die Informationen über den erwarteten Kontrollfluß können automatisch vom Compiler generiert werden [Wildner]. Das Timing des Kontrollflusses kann durch andere automatisierte Analysen vorausgesagt werden. Die zugelassenen Zustände der Anlage (oder des Systems) können im Monitor auf einem nicht schreibbaren Speicherbereich (z.B. ROM Read only Memory) kodiert werden, so daß der Monitor die Anlage und den Steuerungszustand auf ihre Zulässigkeit prüfen kann. Weiterhin kann der Monitor auch Plausibilitätsprüfungen, Umkehrtests und Sicherheitsprüfungen der Ergebnisse des Arbeiters durchführen. Was er nicht kann, ist weder die Integrität der internen Daten des Arbeiters noch seine "Asserts", Vorbedingungen und Nachbedingungen prüfen. Die Verwendung eines Monitors ersetzt nicht die internen Prüfungen (Robustheit), denn der Arbeiter kann dadurch seine eigenen Fehler schneller erkennen und die Fehlerverbreitung wird effektiver gestoppt. Auf der anderen Seite kann ein Monitor sicherer Fehler erkennen. Beide Module zusammen bilden ein neues vertrauenswürdiges Modul mit erhöhter Sicherheit.
Der Monitor muß unabhängig vom Arbeiter lauffähig sein. Er darf nicht auf eine Kommunikation mit dem Arbeiter warten oder seine Berechnungen davon abhängig machen. Um eine höhere Sicherheit gegen Störungen durch den Arbeiter zu erreichen, soll der Monitor mit einer getrennten Hardware (Prozessor, Speicher, Sensorik usw.) laufen. Wenn das nicht möglich ist, muß der Monitor mit einer höheren Priorität laufen, und seine Adressbereiche müssen (per MMU) geschützt werden, um seine Integrität so weit wie möglich zu erhalten. Aber es bleibt die Unsicherheit, daß der Prozessor sich aufhängen kann, eventuell durch einen Fehler des Arbeiters oder im Betriebssystem. Dies muß durch einen Watchdog (Timer) aufgefangen werden, um auch in diesen Fällen eine Notfunktion aktivieren zu können (meistens aber zu spät). Wenn der Monitor auf dedizierter Hardware läuft, kann man ein extrem einfaches (oder gar kein) Betriebssystem anwenden. Die Sicherheitsbedingungen werden dann zyklisch und nicht interruptgesteuert geprüft. Der Arbeiter hat dagegen eine viel komplexere Funktion und kann aus mehreren Tasks bestehen. Daher wird er kaum auf ein Betriebssystem verzichten können (höhere Komplexität impliziert höhere Absturzgefahr).
Wenn der Monitor ein Fehlverhalten beim Arbeiter entdeckt, kann er ihn zu einem Recovery zwingen. Wärend der Arbeiter sein Recovery ausführt, muß jemand anderes die Steuerung der Anlage übernehmen, z.B. ein anderer diversitärer Arbeiter (Primär-/Schattenmodul-Prinzip, siehe unten). Bei knappen Ressourcen kann der Monitor in der Zwischenzeit die Kontrolle übernehmen, aber mit einer minimalen Notfunktionalität. Die einfachste Lösung ist, die Anlage sicher herunterzufahren. Eine etwas kompliziertere Lösung ist, die Anlage mit einer begrenzten Notfunktionalität weiter zu betreiben, bis der Arbeiter wieder lauffähig ist. In jedem Fall braucht der Monitor nicht die vollständige Funktionalität der Anlage zu implementieren und muß daher viel einfacher, durchschaubarer und dadurch sicherer implementiert werden.
Die Kopplung zwischen Monitor und Arbeiter kann folgende Formen annehmen:
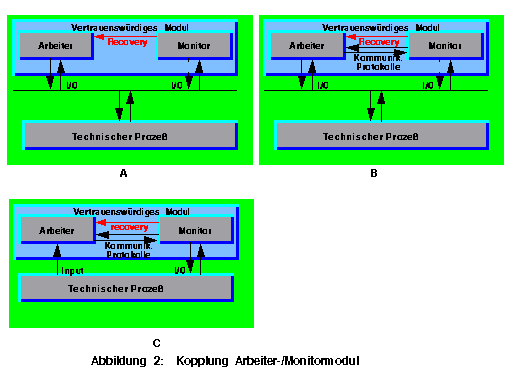
1. Der Monitor liest direkt regelmäßig den Zustand der kontrollierten Anlage, um fehlerhafte Situationen zu erkennen. Software und Hardware brauchen keine Erweiterungen, aber die Fehler werden sehr spät erkannt, möglicherweise nach dem Eintreten einer gefährlichen Situation (Abbildung 2,A). Wenn der Monitor eine verdächtige Situation erkennt, aktiviert er eine Notfunktion und zwingt den Arbeiter zum Recovery.
2. Wie 1., aber der Monitor überwacht direkt alle I/O-Aktivitäten des Arbeiters. Dadurch kann er Fehlentscheidungen und unsichere Handlungen schneller erkennen. Diese Lösung könnte eine extra Hardware benötigen.
3. Wie 1. oder 2., aber der Arbeiter und der Monitor melden sich regelmäßig gegenseitig an. Die Meldungen enthalten Zustandsinformationen und Absichten (Abbildung 2,B). Dies ermöglicht eine Früherkennung von Fehlern und außerdem wird auch der Monitor überwacht. Dies erhöht die Sicherheit der Steuerung. Wenn der Arbeiter ein verdächtiges Verhalten beim Monitor entdeckt, kann er nichts direkt unternehmen, nur den Operator informieren, damit er die nötigen Handlungen durchführt. Die Kommunikationsprotokolle zwischen beiden Modulen erlauben weitere Prüfungen, wie z.B. das korrekte Einhalten des Protokolls - ein Protokollfehler kann auf ein Kontrollflußproblem deuten -, Timings, Randbedingungen und Lebendigkeit von beiden Modulen. Der Nachteil ist die höhere Komplexität des Systems durch die Kommunikationsprotokolle.
4. Der Monitor hat die direkte Kontrolle über die Anlage. Der Arbeiter kann Befehle nur über den Monitor weitergeben. Der Monitor prüft jeden Befehl und sendet nur sichere Befehle weiter. Notfunktion und Recovery werden wie bei 1. implementiert (Abbildung 2,C).
3. Diversitäre Entwicklung
Die robusten und die vertrauenswürdigen Module (mit Monitor) können höchstens Entwicklungsfehler erkennen und notfalls eine Notfunktion (z.B. Fail safe) starten. Fehlertoleranz gegen Entwicklungsfehler erfordert eine volle diversitäre Entwicklung ohne einen einzigen "Single point of global failure", nicht wie in Abbildung 3. In diesem Fall werden die Fehler aus der Anforderungsspezifikation in allen Versionen vorhanden sein. Und gerade bei der Anforderungsspezifikation sind die meisten Fehler zu erwarten. Das gleiche gilt, wenn ein Entwickler in mehreren Entwicklungsteams beteiligt ist. Seine Denkfehler werden sich in allen seinen Teams verbreiten. Auch wenn mehrere Teams dieselben Werkzeuge (z.B. Compiler) benutzen, können gleiche Fehler in verschiedenen Versionen vorkommen. Daher sollte man verschiedene Teams, die nicht miteinander sprechen, verschiedene Spezifikationen, Werkzeuge, Sprachen, Betriebssysteme, Hardware, Prozessoren usw. einsetzen. Dies zeigt den Aufwand von echt diversitären Entwicklungen und ist trotzdem keine Garantie für Fehlerfreiheit.
Fehlertoleranz gegen (einige) Entwicklungsfehler kann durch die Verwendung von zwei diversitären (verschiedenen) vertrauenswürdigen Modulen nach dem Prinzip der primären und Schattenmodule erreicht werden oder auch durch die TMR-Methode (dreifache Modulredundanz) mit drei verschiedenen Entwicklungen.
Das Prinzip der Primären und Schattenmodule basiert auf zwei parallelen vertrauenswürdigen Modulen. Eines der beiden ist als primäres Modul (Aktuatormodul) im Dienst, das zweite ist ein Schattenmodul (Monitormodul), das mitläuft, aber sich nicht einmischt. Das Primärmodul hat die Kontrolle, bis es einen Fehler in sich selbst erkennt, dann zieht es sich selbständig zurück, um ein Recovery auszuführen. Das Schattenmodul wird sofort zum Primärmodul und übernimmt die Kontrolle. Wenn das ausgefallene Modul wieder betriebsbereit ist, übernimmt es die Rolle des Schattenmoduls und bleibt in Bereitschaft. Wenn das Schattenmodul einen Fehler in sich selbst erkennt, führt es ein Recovery in aller Stille durch. Das Schattenmodul wird erst aktiv, wenn es merkt, daß die erwartete Reaktion des primären Moduls nicht rechtzeitig ankommt oder nach Absprache zwischen beiden Modulen (Kommunikationsprotokolle). Hier hat man nicht das Problem vom Vergleich der Ergebnisse der beiden Module, sie können unterschiedliche (korrekte) Ergebnisse produzieren. Wenn das primäre Modul behauptet, seine Ergebnisse seien korrekt, kann man ihm glauben, obwohl ein gewisses Mißtrauen gegenüber dem gesamten System immer bleiben sollte.
Bei einer TMR-Konfiguration werden drei similare (gleiche) Module benutzt, die die gleiche Aufgabe bearbeiten. Ein Vergleicher prüft, ob alle drei gleiche Ergebnisse liefern. Ist das der Fall, wird das Ergebnis weitergeleitet. Ist ein Ergebnis unterschiedlich, wird es ausmaskiert (ignoriert) und die zwei gleichen werden weitergeleitet (demokratisch). Sind alle 3 Ergebnisse unterschiedlich, so hat man große Probleme. Aber Vorsicht: Daß zwei Ergebnisse gleich sind, bedeutet nicht unbedingt, daß sie korrekt sind, sondern nur, daß sie sehr wahrscheinlich korrekt sind. Es kann auch vorkommen, daß der korrekte Wert ausmaskiert wird und die falschen weitergeleitet werden. Sicherer ist es, noch weitere Plausibilitätsprüfungen einzubauen oder die TMR-Technik mit den vertrauenswürdigen Modulen zu kombinieren.
Der Vorteil der TMR-Technik ist, daß (scheinbar) fehlerhafte Ergebnisse "on-the-fly", also ohne Zeitverlust, ausmaskiert werden können. Auch bei internen Fehlern werden korrekte Ergebnisse mit korrekten Timing geliefert. Die Nachteile sind ihr hoher Aufwand und das Vergleichen von Ergebnisse. Eine TMR-Software-Lösung steht meist vor einem unlösbaren Problem: Das Vergleichen der Ergebnisse ist nicht immer möglich. Alle Versionen können verschiedene Ergebnisse liefern, ohne falsch sein zu müssen. Ein komplexes Problem hat eben viele mögliche Lösungen und das besonders bei technischen Systemen. Es gibt keine allgemeine Lösung für dieses Problem. Man muß für jede Applikation sehen, ob eine TMR-Lösung möglich ist. Oft wird das Problem gelöst, indem alle diversitären Entwicklungen von derselben Spezifikation ausgehen, wo die Ergebnisse sehr genau beschrieben werden, so daß dem Entwickler kaum ein Entscheidungsfreiraum bleibt. Dies ist aber keine Lösung, denn eine so genaue Spezifikation wird sehr groß und fehlerhaft. Sie ist fast das Programm selbst. Dies ist dann keine echte diversitäre Entwicklung. Die Spezifikation ist der "Single point of global failure". Eine andere Möglichkeit ist es, bei der Spezifikation eine Vergleichbarkeit der Ergebnisse zu definieren. Alle Ergebnisse müssen bestimmte Merkmale vorweisen, damit sie vergleichbar sind, z.B Wertebereiche, Zustandsindikatoren, Vergleichspunkte, Synchronisationspunkte. Auch müssen Vorgaben gemacht werden, wie die Module auf die Vergleichsergebnisse reagieren sollen. In diesem Fall soll die Spezifikation so detailliert sein, daß ein Vergleich der verschiedenen Versionen möglich ist, aber nicht so detailliert, so daß es Verschiedenartigkeit erlaubt.
Eine Lösung mit Primär-/Schatten- vertrauenswürdigen Modulen ist dagegen fast immer möglich und einfacher. Wenn das Arbeiter- und das Monitor-Submodul diversitär entwickelt worden sind, hat man eine hohe Sicherheit erreicht. Besonders kritisch wird es, wenn die beiden diversitären Entwicklungen ähnliche Fehler haben und beide Module sich gleichzeitig zurückziehen, um ein Recovery zu machen. Dagegen hilft, wenn das Schattenmodul sich nur mit der Erlaubnis des primären Moduls zurückziehen darf. Um Entwicklungskosten zu sparen, kann das Schattenmodul einfacher als das primäre Modul sein und nur eine Kern- (Not-) Funktionalität anbieten, und nur solange das primäre Modul ein Recovery durchführt und wieder lauffähig ist.
Aber Vorsicht: Mit Einführung von Redundanz steigt die Komplexität des Systems und damit wiederum die Fehleranfälligkeit, und eine diversitäre Entwicklung ist keine sichere Garantie. Statistiken haben gezeigt, daß viele Probleme von vielen Programmierern identisch falsch gelöst werden. Es gibt Fälle, die fast alle übersehen oder gleich falsch implementieren. Z.B. beim Berechnen von Drehungen vergessen viele Programmierer zu überprüfen, ob der Winkel gleich oder über 360 Grad ist. Bei der Berechnung der Flughöhe als Funktion des Luftdrucks vergessen fast alle Programmierer, daß das Tote Meer tief unter dem Meeresspiegel liegt. Man findet sehr oft Programme mit derselben Funktionalität, die unabhängig voneinander geschrieben wurden und trotzdem identisch sind, sogar mit denselben Variablennamen (z.B. Programmierübungen bei Studenten an der Universität).
Weitere Referenzen
Mein Buch: Sichere und Fehlertolerante Steuerungen

[Formale Methoden]
./public
->Formale Methoden in der Softwareentwicklung heute und morgen
Die Rolle der Sicherheit in der Software, Formale Methoden (def.), Eigenschaften einer Entwicklung mit formalen Methoden, Validierung,Verifikation
[konzeption]
./public
->Konzeption sicherheitsrelevanter eingebetteter Systeme
Vereinfachen, Kooperation Mensch-Maschine, Risiken und Gefahren erkennen, Gefahren beherrschen
[Wildner]:
Compiler Assisted Self-Checking of Structural Integrity. Dissertation,
Universität Potsdam, 1997
Monitoring des Kontrollflusses bei Steuerprogrammen, um Fehler frühzeitig zu erkennen; Validierung und Verifikation, Software Fehlertoleranz, Fehlerinjektion.
[FTCS-28]:
Annual international Symposium on Fault-Tolerant Computing
http://www.chillarege.com/ftc
Fehlertolerante Architekturen, Transaktionen, Verteilte und Echtzeit-Verbindungsnetzwerke, Software und in VLSI.
./seminar
Seminar an der Technischen Universität Berlin über Sicherheit,
Hazard-Analyse, Fehlertoleranz, Analysen von Unfällen und Entwicklung sicherheitsrelevanter eingebetteter Systeme.