Fehlertoleranz und Industrie Computer
GMD-FIRST (http://www.first.fhg.de)
Fehlertoleranz wird benötigt bei Systemen, bei denen ein Fehler oder ein Ausfall (Anomalien) tödliche Folgen haben (sicherheitskritische Anwendungen) oder große Verluste verursachen kann. Bei solchen Systemen gibt es nur eins, was noch schlimmer als ein Systemausfall sein kann: das blinde Vertrauen, das System sei sicher. Fehlertoleranz wird auch bei Systemen benötigt, bei denen keine Reparaturen möglich sind, wie z.B. bei Satelliten oder Unterwasserstationen.
Ein fehlertolerantes System soll seine Funktion weiter erfüllen, auch bei Fehlern und internen Ausfällen. Es darf Fehler enthalten aber es darf nicht Fehler propagieren oder sichtbar machen. Seine Fehler, Ausfälle oder Störungen dürfen keine externe Wirkung zeigen. Ein großer Teil der Sicherheit hängt von der Fähigkeit des Systems ab, während der Laufzeit solche Anomalien zu entdecken und zu behandeln, bis Hilfe kommt - oder wenn keine Hilfe zu erwarten ist, dann solange es geht. Diese Anomalien können unentdeckte Entwicklungsfehler, Störungen, Ausfälle oder unerwartete Situationen sein [Pendel].
Umgang mit Prozessoren und aktiven Modulen
Aktive Module, wie z.B. Prozessor-Module, sind Masters und können, im Gegensatz zu den Slave-Modulen (einfache I/O Devices, Sensoren, Aktuatoren), die sich nur auf Befehle des Masters hin melden, selbständig handeln. Deshalb können sich Anomalien in diesen Modulen schneller im System verbreiten und weitere Anomalien in anderen Modulen verursachen. Ein aktives Modul ist in der Lage, andere Module durch Nachrichten, Buszugriffe, Schreiben im fremden Speicher usw. zu stören. Die Auswirkungen dieser Anomalien sind dann am dramatischsten, wenn die Module auch die Aktuatoren direkt kontrollieren. Beispiele für Prozessormodulfehler sind Steuerungsstillstand (keine Reaktion mehr) oder noch folgenschwerer: unkontrolliertes Verhalten. Diese Anomalien sind nicht nur die gefährlichsten, sondern leider auch die am meisten zu erwartenden (vielleicht mit Ausnahme der mechanischen Ausfälle). Der Grund dafür ist die hohe Komplexität dieser Module. Obendrein sind hier auch meistens systematische Fehler (z.B. Entwicklungsfehler), die sich nicht so leicht mit Redundanz beheben lassen, zu erwarten.
Wirkliche Komponentenausfälle treten bei diesen Modulen selten auf (z.B. einmal in 2 Jahren), transiente (Random-)Fehler wie z.B. bit-kipper sind viel öffter zu erwarten. Dies ist besonders bei erhöhter Strahlung der Fall wie z.B. in der Luft- und Raumfahrt (in der Raumfahrt-Terminologie sogenannte Single event upsets (SEUs)). Bei transienten Fehlern kann das Modul weiter benutzt werden, ohne daß eine Reparatur erforderlich ist. Das Modul muß nur ein Recovery durchführen und kann danach weiterlaufen. In der Zwischenzeit muß entweder ein anderes (redundantes) Modul seine Aufgabe übernehmen oder die Recovery-Zeit müßte so kurz sein, daß das Recovery zwischen zwei Steuerungszyklen stattfinden könnte. Letzteres ist aber sehr selten der Fall.
Modulfehler können intern im Modul behandelt werden oder sie werden von außen sichtbar (sie haben sichtbare Folgen) und müssen extern behandelt werden. Für eine interne Behandlung müssen Prozessoren und anderen Modulkomponenten redundant ausgeführt werden. Für eine externe Behandlung werden die Module als ganze redundant ausgeführt. In diesem Fall wird eine modulinterne Redundanz überflüssig. Die Ergebnisse und Handlungen von redundanten Modulen müssen verglichen werden, um Fehler zu erkennen und zu behandeln. Diese Vergleichsfunktion kann als dedizierte Hardware implementiert werden oder von einem anderen Prozessormodul ausgeführt werden.
Sichtbare Folgen eines Modulfehlers
Abhängig von den Umständen, vom Fehlertyp und von der eingebauten Fehlererkennung und -behandlung können die Anomalien in den aktiven Modulen von unterschiedlicher Tragweite sein. Je weniger die Module sich selbst prüfen, desto stärker und mächtiger muß eine externe Überwachung sein, um die Sicherheit zu garantieren. Normalerweise müßte eine externe Überwachung in der Lage sein, alle folgenden Auswirkungstypen zu behandeln:
0. Am bedrohlichsten: Unkontrolliertes Versagen. Das Modul verhält sich unvorhersehbar, wie z.B. beim Verlust des Prozessor-Kontrollflusses. Das Modul meldet keine Fehler und kann andere stören oder sabotieren. Wenn man vom "Worst-Case" ausgeht, muß das betroffene Modul als ein bösartiger Saboteur mit bösen Absichten betrachtet werden. Wo es Schaden anrichten kann, wird es das auch tun. Es kann sogar eine Rekonfiguration oder ein Recovery verhindern. Dies kann bei Modulen ohne eigene Überwachung oder Fehlererkennung geschehen. Für die Systemsicherheit müssen dann externe Überwachungseinheiten, wie z.B. die anderen (redundanten) Module oder Vergleichsmodule vorhanden sein. Eine externe Einheit muß in der Lage sein, solche Module auszuschalten und zu isolieren, z.B. durch Tristate-Buffers, Reset oder - im Extremfall - die Stromversorgung des Moduls zu unterbrechen (allerdings ist dann ein Recovery des Moduls nicht mehr möglich).
1. Das Modul liefert falsche Ergebnisse bzw. zum falschen Zeitpunkt, ohne es zu merken und zu melden. Der Grund dafür ist meistens ein transienter Fehler. Die nächste Berechnung könnte wieder richtig sein, ist es aber meistens nicht. Solange genügend Redundanz vorhanden ist, kann die externe Überwachung den falschen Wert ausmaskieren. Falls das fehlerhafte Modul seine eigenen Fehler nicht erkennt, muß es von außen zum Recovery gezwungen werden. Dies muß auch bei transienten Fehlern geschehen, da diese Module nicht mehr vertrauenswürdig sind .
2. Stillstand-Versagen (Fail silence). Wenn ein Modul einfach hängt (z. B. beim Verlust des Prozessor-Kontrollflusses) und sich nicht mehr meldet, muß es zum Recovery (z. B. durch eine Watchdog-Logik) gezwungen werden. Meistens wird die Watchdog-Funktion intern in den aktiven Modulen implementiert, jedoch auch von außen muß es möglich sein, ein Recovery zu erzwingen.
3. Halt-Versagen (Fail stop) ist ähnlich dem Stillstand-Versagen, aber mit dem Unterschied, daß das Modul seine Fehler und bzw. Situation vor dem Stillstand, oder bevor das Recovery gestartet wird, noch meldet. Dies macht es etwas leichter und die externe Fehlerbehandlung sicherer.
4. Das Modul kann seine eigenen Fehler erkennen, es liefert nur richtige Ergebnisse oder im Fehlerfall gar keine. Nach der eigenen Fehlererkennung wird ein Recovery durchgeführt, so daß das Modul bald wieder richtige Ergebnisse liefern kann.
5. Das Beste: Das Modul kann seine eigenen Fehler intern erkennen und behandeln, ohne daß sie außerhalb des Moduls bemerkbar werden (ein in sich fehlertolerantes Modul).
Modulinterne Behandlung der Modulfehler
Eine interne Fehlererkennung und -behandlung muß alle Modulkomponenten abdecken:
1. den Prozessor, meistens in der Form eines Microcontrollers,
2. den Speicher und
3. den Busanschluß.
Die Microcontroller haben einen hohen Integrationsgrad, aber kaum eine Unterstützung für interne Fehlererkennung und -behandlung. Grobe Fehler, wie z.B. wenn der Prozessor hängen bleibt oder sich verläuft, können durch eine Watchdog-Logik erkannt und grob (Holzhammer: Reset) behandelt werden. Für eine feinere Überwachung muß man meistens den Prozessor duplizieren (Duplex-Prozessor) oder verdreifachen. Transiente interne (seltene) Prozessorfehler können behandelt werden, indem jeder Task zweimal durchläuft und bei unterschiedlichen Ergebnissen noch ein drittes Mal, um das richtige Ergebnis zu identifizieren. Speicherfehler können durch Parity, EDC-Codes (Error Detection and Correction), CRC (Cyclic Redundant Codes) auf Blockebene, mehrfache Kopie der Daten und Adressraumschutzregister (eher für Softwarefehler) erkannt und teilweise behandelt werden. Dieselben Methoden plus Timeouts können auch für den Busanschluß benutzt werden.
Modulexterne Behandlung durch redundante Module
Das effektivste ist, das gesamte Modul als ganzes redundant auszuführen und extern einen extra Überwachungsmechanismus einzubauen. Die Überwachung braucht eine Referenz, um Anomalien zu erkennen, wie z.B. Plausibilitätsprüfungen oder mehrere redundante Module, deren Ergebnisse sie vergleichen kann. Aber Vorsicht: Das Problem der Vergleiche ist hier schlimmer als bei den Sensoren, denn kleine Input-Unterschiede können zu total unterschiedlichen Ergebnissen führen. Dies passiert bei Werten nahe an Entscheidungsschwellen z.B.:
if(temp > 123.45) { ... } else { ... }
Bei einem Wert um 123.45 kann eine Sensortoleranz von nur 0.01% zu enormen Unterschieden führen, so daß die Ergebnisse von zwei parallel laufenden Modulen nicht mehr vergleichbar sind. Um dieses Problem zu lösen, braucht der Vergleicher die zusätzliche Information, ob eine Entscheidung nahe am Schwellenwert getroffen wurde. Dies kann helfen, ist aber meistens nicht ausreichend. Weiter unten werden andere Möglichkeiten erläutert.
Der Vergleicher kann als ein extra (Hardware) Modul, das die aktiven Module beobachtet, implementiert werden. Das Problem dabei ist die zusätzliche Komplexität, die eine weitere Gefahr mit sich bringt. Dieses Modul kann zwar viel einfacher als die beobachteten aktiven Module sein und daher weniger fehleranfällig, aber ein Ausfall ist nicht auszuschließen und kann zum "Single point of global failure" werden. Dieses Modul soll deswegen auch redundant ausgeführt werden. Dies bringt wieder neue Probleme, die später behandelt werden.
Die Vergleicher-Aufgabe kann auch von den aktiven Modulen selbst übernommen werden, indem sie sich gegenseitig überwachen und demokratische Entscheidungen treffen, falls es Unterschiede gibt. Das Problem dabei ist, daß ein unkooperatives Modul (siehe Auswirkungstyp 0) großen Schaden verursachen kann.
Eine externe Überwachung erkennt die Fehler zwar später als eine modulinterne Überwachung, dafür hat sie aber mehr Möglichkeiten, wie z.B. Vergleich mehrerer Module, Timingchecks, Synchronisationspunkte für alle Prozessoren, Kommunikationsprotokolle und die Untersuchung der gesendeten Nachrichten, und sie hat auch die Möglichkeit, unkooperative oder verdächtige Module kaltzustellen. Dafür gibt es zwei Möglichkeiten (Abbildung 1): 1.: Man kann alle Busanschlüsse der Module mit Tristate-Buffers versehen, welche unter der Kontrolle der Überwachungseinheit sind. 2.: Man kann die Module mit Widerständen an den Bus anschließen (Isolatoren) und die Überwachungseinheit soll in der Lage sein, den Stromzufluß von jedem Modul getrennt zu unterbrechen. Diese Methode ist ökonomischer, sicherer und man kann dadurch Strom sparen (dies ist wichtig in der Raumfahrt). Der Nachteil dabei ist, daß das abgeschaltete Modul kein Recovery mehr durchführen kann.
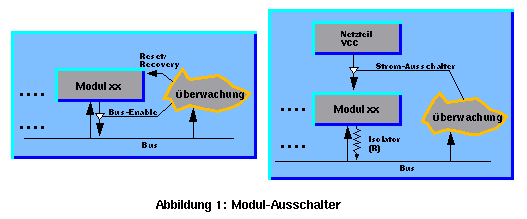
Vertrauenswürdige Module
Mit zwei redundanten aktiven Modulen können Fehler erkannt, aber nicht lokalisiert werden. Ab drei redundanten Modulen können die Fehler erkannt, lokalisiert und ausmaskiert werden, so daß ein Fehler keine Wirkung für die nachfolgen und übergeordneten Module hat. Mit zwei redundanten Modulen kann ein selbstprüfendes übergeordnetes vertrauenswürdiges Modul (Trusted Node oder Modul) aufgebaut werden. Ein vertrauenswürdiges Modul ist partiell korrekt, so daß es nur korrekte Ergebnisse liefert, oder gar keine im Fehlerfall, bis ein Recovery stattgefunden hat. Ein vertrauenswürdiges Modul ist noch nicht fehlertolerant, aber ein guter Baustein dafür. Es kann auch allein als ein "Fail safe"-Modul verwendet werden. Bei dieser Konfiguration soll das Modul eine sichere Reaktion (z.B. Notaus) liefern oder ein Notprogramm starten, wenn ein interner Fehler entdeckt wird.
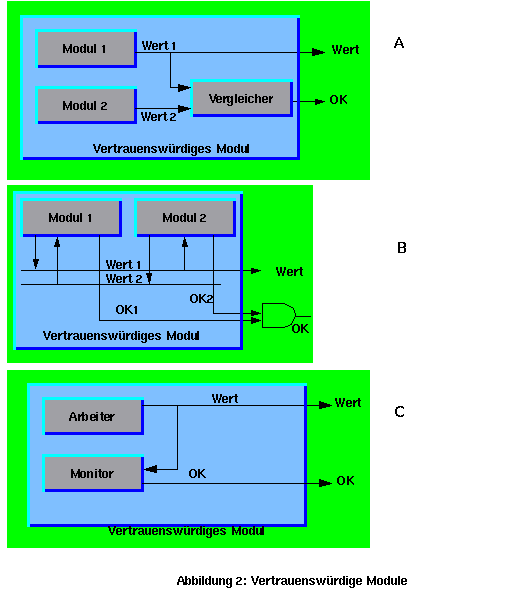
Das Bild 2 zeigt drei Möglichkeiten, ein vertrauenswürdiges Modul aufzubauen (A,B, C). Es liefert nicht nur einen Wert, sondern auch ein Signal (OK), um die Korrektheit des Wertes zu bestätigen. Dieses Signal kann auch dafür benutzt werden, das Modul vom Rest des Systems zu isolieren, falls es unkooperativ aussieht. Die Konfiguration mit dem dedizierten Vergleicher (A) birgt das Problem, daß ein Vergleicherausfall (z.B. er sagt immer OK) unbemerkt bleibt und eine latente Ausfallgefahr für das übergeordnete Modul darstellt. Ein Folgefehler in Modul 1 könnte böse Folgen haben. Man sollte deswegen den Vergleicher doppelt ausführen, beide OK-Signale verknüpfen und Unterschiede melden (B). Wenn Sie aufmerksam gelesen haben, wird Ihnen aufgefallen sein, daß das Problem nicht gelöst wurde, sondern nur verschoben. Bei der zweiten Konfiguration überwachen sich beide Module gegenseitig. Man braucht nur noch die beiden OK-Signale zu verknüpfen und Unterschiede zu melden. Da die Module intelligenter als ein einfacher Vergleicher sind, können raffiniertere Vergleichsalgorithmen (mit Bereichen, Schwellenwerten, Plausibilitätsprüfungen usw.) implementiert werden. Dadurch sind auch Sicherheitsprüfungen wie z.B. verbotene Bereiche, Überschreitung der Betriebsparameter usw. möglich. Eine höhere Sicherheit kann durch eine diversitäre Entwicklung der Module und deren Software erreicht werden (C). So können auch systematische und Entwicklungsfehler erkannt werden. Aber Vorsicht: Dies kann auch zu einer gefährlichen Falle werden (sihe Unten). Bei einer diversitären Entwicklung kann ein Modul als Arbeiter benutzt werden, während der andere nur Plausibilität, Sicherheit und Timing der Berechnungen prüft. Die Prüfung kann als einfacher Bedingungstest implementiert werden. Dagegen braucht der Funktionsteil z.B. Servokontrolle, Regelungsschleife, Wegplanung, Wegtracking, Motion-Control, Positionskontrolle, Geschwindigkeitskontrolle u.a. und dazu noch eine Benutzerschnittstelle. Als Beispiel dient eine fahrende Anlage. Eine Sicherheitsanforderung könnte sein "mindestens 3 Meter Abstand zu vorausfahrenden oder stehenden Objekten halten". Die Funktionssteuerung ist komplexer. Sie mißt Geschwindigkeit, Abstand, Neigung, Winkel der Räder und Position, nimmt von einer Datenbasis den gewünschten Weg, berechnet die Sollwerte für die Motoren und andere Aktuatoren, kontrolliert die Istwerte und steuert die Aktuatoren. Diese Funktion ist viel komplexer als die entsprechende Sicherheit, die in einer Zeile programmiert werden kann:
Fehlertolerante Konstruktionen
Durch die Verwendung von zwei vertrauenswürdigen Modulen kann ein fehlertolerantes Modul aufgebaut werden, wie die Abbildung 3 zeigt. Eines der beiden ist als primäres Modul (Aktuatormodul) im Dienst, das zweite ist ein Schattenmodul (Monitormodul), das mitläuft, aber sich nicht einmischt. Das Primärmodul hat die Kontrolle, bis es einen Fehler in sich selbst erkennt, dann zieht es sich selbständig zurück, um ein Recovery auszuführen. Das Schattenmodul wird sofort zum Primärmodul und übernimmt die Kontrolle. Wenn das ausgefallene Modul wieder betriebsbereit ist, übernimmt es die Rolle des Schattenmoduls und bleibt in Bereitschaft. Wenn das Schattenmodul einen Fehler in sich selbst erkennt, führt es ein Recovery in aller Stille durch. Das Schattenmodul wird erst aktiv, wenn es merkt, daß die erwartete Reaktion (Signal OK) des primären Moduls nicht rechtzeitig ankommt oder nach Absprache zwischen beiden Modulen (Kommunikationsprotokolle). Hier hat man nicht das Problem vom Vergleich der Ergebnisse der beiden Module, sie können unterschiedliche (korrekte) Ergebnisse produzieren. Wenn das primäre Modul behauptet, seine Ergebnisse seien korrekt, kann man ihm glauben, obwohl ein gewisses Mißtrauen gegenüber dem gesamten System immer bleiben sollte. Das Problem mit Modulen, die sich bösartig verhalten, kann man auf dieser Ebene vernachlässigen, denn jedes vertrauenswürdige Modul wird intern bereits geprüft, und wenn nötig abgeschaltet.
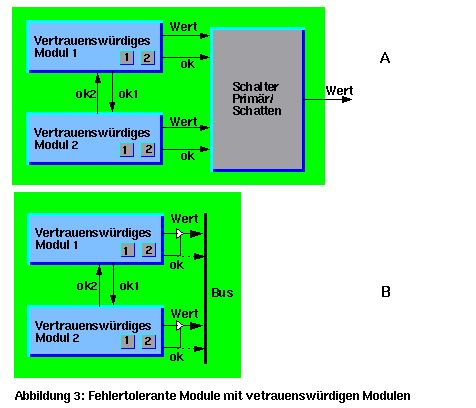
Unangenehm wird es, wenn beide vertrauenswürdigen Module gleichzeitig einen internen Fehler finden, wie z.B. einen systematischen Fehler. Dann ziehen sich beide zurück, um ein Recovery durchzuführen und das System bleibt ohne Kontrolle. Dies kann z.B. passieren, wenn ein Entwicklungsfehler durch interne diversitäre Entwicklung entdeckt wird und beide vertrauenswürdigen Module identisch sind. Ironischerweise könnte es besser gewesen sein, den Fehler nicht zu erkennen, denn nichts zu tun (keine Reaktion der Steuerung) kann schlimmer sein, als etwas falsches zu tun. Dieses Problem kann verhindert werden, indem die parallelen vertrauenswürdigen Module auch diversitär entwickelt werden. Dies ist aber sehr aufwendig, denn man braucht die 4-fache Entwicklung. Ökonomischer ist es, wenn die Module sich absprechen bevor einer sich zurückzieht, um ein Recovery durchzuführen.
Man kann auch direkt fehlertolerante Module konstruieren, ohne vertrauenswürdige Module zu verwenden. Dies basiert auf demokratischen Entscheidungen mit drei oder mehr redundanten Modulen, wobei eine ungerade Anzahl von Modulen die Entscheidungen bei Differenzen einfacher, aber nicht unbedingt sicherer macht. Die Basiskonfiguration besteht aus einer dreifachen Modulredundanz (TMR: Triple Modular Redundancy), wie das Bild 4 zeigt.
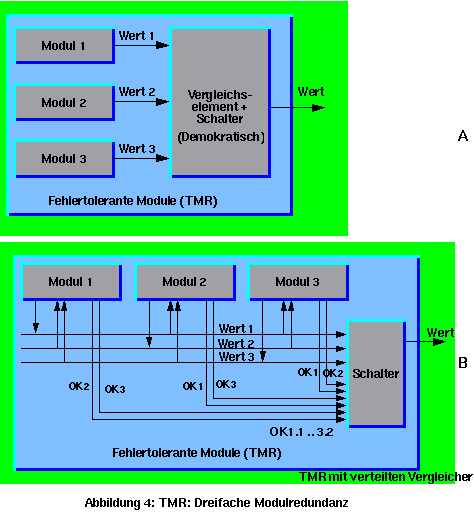
Bei einer TMR-Konfiguration werden drei similare (gleiche) Module benutzt, die die gleiche Aufgabe bearbeiten. Ein Vergleicher prüft, ob alle drei gleiche Ergebnisse liefern. Ist das der Fall, wird das Ergebnis weitergeleitet. Ist ein Ergebnis unterschiedlich, wird es ausmaskiert (ignoriert) und die zwei gleichen werden weitergeleitet (demokratisch). Sind alle 3 Ergebnisse unterschiedlich, so hat man große Probleme. Aber Vorsicht: Daß zwei Ergebnisse gleich sind, bedeutet nicht unbedingt, daß sie korrekt sind, sondern nur, daß sie sehr wahrscheinlich korrekt sind. Es kann auch vorkommen, daß der korrekte Wert ausmaskiert wird und die falschen weitergeleitet werden. Sicherer ist es, noch weitere Plausibilitätsprüfungen einzubauen oder die TMR-Technik mit den vertrauenswürdigen Modulen zu kombinieren.
Der Vorteil der TMR-Technik ist, daß (scheinbar) fehlerhafte Ergebnisse "on-the-fly" ohne Zeitverlust ausmaskiert werden können. Auch bei internen Fehlern werden korrekte Ergebnisse geliefert mit dem korrekten Timing. Die Nachteile sind ihr hoher Aufwand und die bereits erwähnten Probleme bei den Vergleichern. Verschiedene, aber korrekte Ergebnisse können nicht so einfach richtig behandelt werden. Die Vergleichsfunktion kann auf die Module selbst verteilt werden (B), um die nötige Redundanz zu erhalten und um raffinierte Vergleichsalgorithmen implementieren zu können (Bereiche, Schwellentwertentscheidungen u.a.). Extern bleibt nur ein Schalter, der mit den Vergleichsergebnissen gesteuert wird.
Fehlertoleranter Datenfluß
Bis hier blieb ein Problem offen: Die Fehler im externen Vergleicher und/oder Schalter werden nicht toleriert. Wenn mehrere Vergleicher benutzt werden, wird das Problem nur verschoben. Ihre Ergebnisse müssen verknüpft werden, um einen einzigen Wert zu bekommen. Der Verknüpfer ist wiederum nicht fehlertolerant. Auf der anderen Seite ist die Verknüpfung so einfach (nur ein And/Or-Gate), daß man kaum einen Ausfall an dieser Stelle erwarten kann. Es gibt noch zwei weitere Möglichkeiten, das Problem weiter zu verschieben (bis es auf der anderen Seite herausfällt). Solange weitere fehlertolerante Module mit demselben Redundanzgrad benutzt werden, können die Module ohne Vergleicher direkt geschaltet werden (siehe Abbildung 5 A).
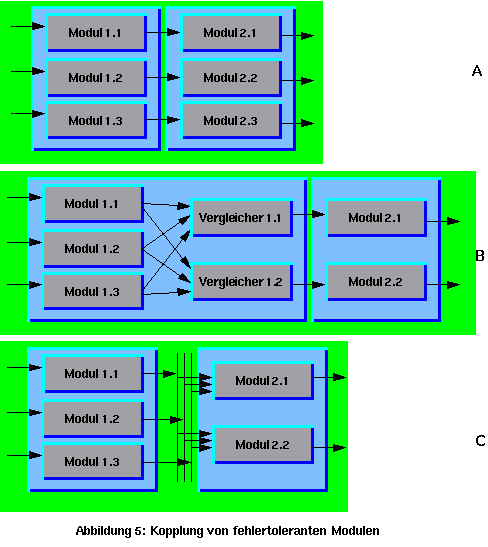
Falls eine höhere Sicherheit oder eine schnellere Fehlerlokalisierung nötig ist, oder wenn der Redundanzgrad der nachfolgenden Module unterschiedlich aber größer Eins ist, kann der Vergleicher redundant ausgeführt werden und die (redundanten) Ergebnisse werden an die redundanten nachfolgenden Module einfach weitergeleitet (B). Es ist ökonomischer und sicherer, die Vergleichsfunktion in die nachfolgenden aktiven Module zu verlagern (C). Sie bekommen alle redundanten Ergebnisse der vorherigen Module und suchen sich das scheinbar richtige Ergebnis heraus. Dies hat auch den Vorteil, daß (per Software) raffiniertere Vergleichsalgorithmen in den aktiven Modulen implementiert werden können.
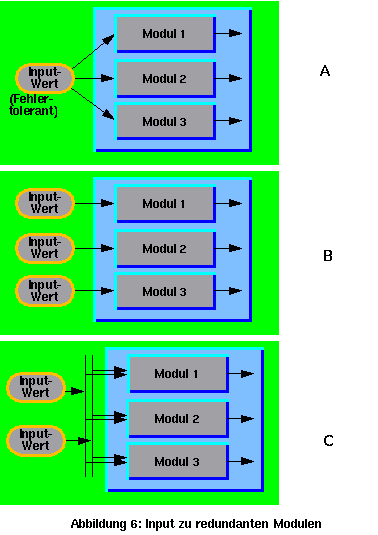
Bis hier wird das Problem der Fehlertoleranz des Vergleichers nicht gelöst, nur weiter verschoben. Aber wenn die letzten Module dieser Kette die (redundanten) Aktuatoren sind, liegt das Problem auf der physikalischen Seite des Systems, auf der Inkonsistenzen nicht existieren, Fehlfunktionen aber noch gefährlicher sind . Dies bleibt noch ein ungelöstes Problem. Aber solange man nur einen Aktuator ohne Redundanz hat, ist das Problem der Fehleranfälligkeit der Verknüpfung (And/Or-Gate) im Vergleich zur Fehleranfälligkeit des Aktuators irrelevant. Ein ähnliches Problem mit ähnlichen Lösungen steht auf der Input-Seite (Sensoren) der aktiven Module. Deswegen müssen die Daten aus den Sensoren auch redundant sein, wie Abbildung 6 zeigt.
Umgang mit verteilten Systemen und Kommunikation
Anstatt dedizierte aktive Module einzusetzen, kann die Funktionalität auf mehrere (mehr als 2) parallel laufende Knotenrechner verteilt werden. Auf diese Weise können viele virtuelle redundante Module als Software-Tasks mit beliebigen Verbindungsstrukturen in (relativ) wenigen Knotenrechnern ausgeführt werden.
Jedes virtuelle (aktive) Modul wird von einem Software-Task ausgeführt, der zusammen mit anderen Tasks in irgendeinem der Knotenrechner laufen kann. Eine TMR-Funktionalität kann erreicht werden, indem seine Aufgabe von drei gleichen Tasks (entspricht drei gleichen virtuellen Modulen) in drei verschiedenen Knoten ausgeführt wird. Die Ergebnisse werden per Nachrichten an den anderen Knoten übertragen, damit sie an die nachfolgenden virtuellen Module (andere Tasks) weitergeleitet werden. Die Empfänger-Tasks führen eine Vergleichsfunktion der redundant empfangenen Werte durch, um die richtigen Daten auszuwählen und um Fehler zu erkennen und zu melden. Es ist zu bemerken, daß der Vergleicher nicht auf Knotenebene sondern auf Taskebene arbeitet. Die Ergebnisse der Knoten sind nicht vergleichbar, denn sie machen nicht das gleiche. Bei vier oder mehr Knoten werden sie nicht die gleichen Tasks ausführen, die Tasks können Knoten wechseln und die Knoten, die zufälligerweise dieselben Tasks haben, werden sie auch nicht in derselben Reihenfolge ausführen, denn die Reihenfolge wird dynamisch vom lokalen Scheduler festgelegt.
Die Knotenrechner könnten selbst als fehlertolerante Module oder als vertrauenswürdige Module implementiert werden. Dies ist aber weder nötig noch ökonomisch. Die Fehlertoleranz-Funktion kann auch ohne weiteren Aufwand auf Taskebene per Software implementiert und in den Knoten verteilt werden. Aber Vorsicht: Dadurch steigt die Komplexität (und Gefahren) der Software. Die Tasks in den Knoten müssen in der Lage sein, Fehler von anderen Tasks, die in anderen Knoten laufen, zu erkennen, zu lokalisieren und ihre Auswirkungen zu begrenzen. Mit Hardwareunterstützung muß es möglich sein, daß jeder Knoten von den anderen Knoten ausgeschaltet oder zum Recovery gezwungen werden kann. Diese Maßnahme darf aber nicht von einem einzigen Knoten allein durchführbar sein, sonst könnte ein fehlerhafter Knoten alle anderen ausschalten, bevor sie etwas merken. Mindestens zwei Knoten müssen so eine Maßnahme beantragen, damit sie durchgeführt wird. Eine Mehrheit ist nicht nötig, da bei einer TMR-Funktionalität nur drei Knoten für drei Tasks beteiligt werden. Ein Fehler in einem Task wird von höchstens zwei anderen Tasks (und damit Knoten) bemerkt.
Knotenausfälle werden toleriert, indem seine laufenden Tasks (virtuelle Module) in den restlichen Knoten verteilt und restartet (Recovery) werden: Migration von Tasks. Dadurch kann die Anzahl der Tasks (virtuelle Module) trotz Ausfällen konstant gehalten werden und der Fehlertoleranzgrad wird angehalten, z.B. kann ein TMR-System (Dreifache Modulredundanz) nach einem Knotenausfall wieder als TMR auf anderen Knoten umkonfiguriert werden. Wäre das TMR in physikalischen Modulen implementiert, würde das System nach einem Modulausfall nicht mehr fehlertolerant sein. Das verteilte System erlaubt, den Fehlertoleranzgrad zu behalten, aber nur solange genügend Knotenrechner (drei oder mehr) und Rechenleistung vorhanden sind. Die übriggebliebenen Knoten werden durch die Migrationen von Tasks höher belastet und das Timing des Systems wird kritischer. Um Timing-Fehler zu vermeiden, sollten die Tasks priorisiert werden, so daß in kritischen Fällen (nach mehreren Knotenausfällen) die unwichtigen Funktionen (z.B. die Klimaanlagesteuerung) keine Rechnerzeit von den wichtigen (z.B. Fluglagestabilisierung ) wegnehmen. Noch besser als die unwichtigen Funktionen warten zu lassen, ist es, sie kontrolliert zu terminieren, so können sie noch einen sicheren Zustand hinterlassen, bevor sie verschwinden. Dieselbe Migrationsfunktion kann auch für Lastenausgleich benutzt werden, ist z.B. ein Knoten überlastet, während andere kaum etwas zu tun haben, dann können einige Tasks zu den unterbelasteten Knoten migriert werden. Tasks, die nicht aus Fehlergründen migriert werden, können mit ihrem gesamten Kontext (wie mobile Agenten) intakt zu einem anderen Knoten transportiert werden, so daß sie sofort weiterarbeiten können, ohne ein Recovery durchführen zu müssen. Tasks, die wegen eines (Knoten-) Fehlers migrieren, müssen ein Recovery durchführen.
Der Knotenanschluß zum Verbindungsnetzwerk muß nicht unbedingt redundant (z.B. doppelt) ausgeführt werden. Wenn das Verbindungsnetz doppelt ausgeführt wird, dann braucht jeder Knoten aus Konstruktionsgründen auch einen doppelten Anschluß. Wenn nur ein Verbindungsnetzwerk mit genügend interner Redundanz benutzt wird, dann ist ein doppelter Anschluß nicht nötig. Ein Knotenanschluß-Ausfall ist viel unwahrscheinlicher als ein Knotenausfall und kann genauso wie ein Knotenausfall behandelt werden.
Die übertragenen Nachrichten müssen in vielerlei Hinsicht geschützt werden: gegen Übertragungsfehler können sie durch CRC und Hash-Codes geschützt werden, gegen Verlust durch Numerierung der Nachrichten, gegen zu große Übertragungsverzögerungen durch Zeitstempel beim Senden, gegen bösartige Handlungen (z.B. bei unkontrolliertem Knotenverhalten) durch Authentifikation des Senders (Kryptologie). Alle diese Möglichkeiten müssen von den Kommunikationsprotokollen unterstützt werden, um Anomalien zu erkennen. Die Behandlung kann durch Sendewiederholungen (Retries) und Rerouting (einen anderen Weg durch das Verbindungsnetzwerk suchen) geschehen.
Weitere Referenzen
Mein Buch: Sichere und Fehlertolerante Steuerungen

[[Hazard Analyse]
./public
->Analysen der Anlagen-Sicherheit und Gefahren (Hazard-Analyse)
Gefahr, Fehler und Unfälle, Vorwärts- und Rückwärts-Suche,Top-Down und Bottom-Up Suche, Sammeln und Protokollieren von Informationen, Checklisten, Ereignisbaumanalyse (ETA: "Event-tree-analysis"), Fehlerbaumanalyse (FTA: "Fault-tree-analysis"), Ursache-Wirkungs-Analyse (CCA / CEA: "Cause-Effect-analysis"), Ausfallarten- und Wirkungs-Analyse (FMAE: "Failure modes and effects")
[konzeption]
./public
->Konzeption sicherheitsrelevanter eingebetteter Systeme
Vereinfachen, Kooperation Mensch-Maschine, Risiken und Gefahren erkennen, Gefahren beherrschen
[pendel]:
./public
-> Das Pendeln zwischen Sicherheit und Gefahr
Sicherheit und ähnliches, Die Natur der Fehler, Der direkte Weg vom Fehler zum Unfall, Das System in seiner ungewissen Umgebung
[Neil Storey]:
Safety-critical computer systems; Addison-Wesley, 1996.
Sicherheitsaspekte, Fehlertoleranz, Hazard-Analyse, Risiko-Analyse, Entwicklung von sicherheitsrelevanten Systemen, Formale Methoden.
[FTCS-28]:
Annual international Symposium on Fault-Tolerant Computing
http://www.chillarege.com/ftc
Fehlertolerante Architekturen, Transaktionen, Verteilte und Echtzeit-Verbindungsnetzwerke, Software und in VLSI.