Fehlertoleranz gegen IO- Hardwarefehler
S. Montenegro (.)
email: sergio@first.fhg.de
GMD-FIRST (http://www.first.fhg.de)
Rudowerchaussee 5
12489 Berlin
Tel: 030/6392-1878
Fax: 030/6392-1805
Fehlertoleranz wird benötigt bei Systemen ohne einen stabilen sicheren Zustand, bei denen ein Fehler oder ein Ausfall (Anomalien) tödliche Folgen haben (z.B. fliegende Flugzeuge) oder große Verluste (z.B. Telefonnetzwerke) verursachen kann. Fehlertoleranz wird auch bei Systemen benötigt, bei denen keine Reparaturen möglich sind, wie z.B. bei Satelliten oder Unterwasserstationen.
Während der Laufzeit muß das System (alleine) mit vielen Anomalien zurechtkommen, z.B. unentdeckte Entwicklungsfehler, Störungen, Ausfälle und unerwartete Situationen. Das einzig Sichere dabei ist, daß irgendwelche Anomalien eintreten werden.
Hier wird erklärt, wie ein fehlertolerantes System seine Funktion trotz Anomalien weiter erfüllen kann und wie ein sicheres System seine Funktion unterbrechen kann, ohne eine Gefahr zuzulassen. Die Behandlung einer Anomalie ist unterschiedlich, je nachdem wo sie aufgetreten ist und um was es sich handelt. Deswegen werden sie in folgenden Kategorien angegangen: Sensoren, Aktuatoren, Prozessoren und Kommunikation.
Ein fehlertolerantes System soll seine Funktion weiter erfüllen, auch bei Fehlern und internen Ausfällen. Es darf Fehler enthalten, aber es darf keine Fehler propagieren oder sichtbar machen. Seine Fehler, Ausfälle oder Störungen dürfen keine externe Wirkung zeigen. Ein großer Teil der Sicherheit hängt von der Fähigkeit des Systems ab, während der Laufzeit solche Anomalien zu entdecken und zu behandeln, bis Hilfe kommt - oder wenn keine Hilfe zu erwarten ist (z.B. Satelliten), dann solange es geht. Die Fehlertoleranz kann in 6 Stufen gestaffelt werden. Nicht nur die Kosten, sondern auch die Geschicklichkeit der Entwickler bestimmen die Fehlertoleranzstufe des Systems:
0: Keine Fehlertoleranz: Das System hat mindestens eine Stelle, deren Versagen den Verlust der kritischen Funktion bewirkt ("Single point of global failure").
1: Erhalt der kritischen Funktion: Es gibt keine Stelle, deren Versagen den Verlust der kritischen Funktion bewirken kann.
2: Degradierung: Die kritische Funktion geht niemals verloren. Die nicht kritische Funktion darf nicht vollständig verloren gehen, sie wird nur degradiert oder begrenzt.
3: Temporale Degradierung: Wie 1. oder 2., aber nur für eine kurze Zeitperiode, während das System sich rekonfiguriert und ein Recovery der verdächtigen Komponenten durchführt.
4: Vollständige Fehlertoleranz: Das System erfüllt seine völlige Funktion trotz vorhandener Fehler und/oder interner Ausfälle für einen begrenzten Zeitraum weiter.
5: Nonstop (continuous availability oder ununterbrochene Verwendbarkeit): Wie die Stufe 4 (aber auch Stufen 1 bis 3 wären denkbar), aber die Reparaturen und der Komponentenaustausch werden im Betrieb durchgeführt, ohne das System anzuhalten oder seine Funktionalität zu beschränken, d.h. es muß trotz Ausfällen unbestimmt lange arbeiten können, wie z.B. Stromnetze und der Vermittlungskern der Telefonzentralen.
Bisher war die Rede von einer einzigen Ausfallstelle oder Anomalie, aber ein Ausfall kommt selten allein! Es ist zu erwarten, daß mehrere Anomalien eintreten, bevor der Defekt behoben werden kann (wenn überhaupt). Bei einem einzigen internen Ausfall kann ein einfaches fehlertolerantes System weiterarbeiten, aber weitere Ausfälle können sich gefährlich auswirken. Das System ist dann in einem latenten Systemausfall-Zustand, der noch nicht gefährlich ist, aber kombiniert mit weiteren internen Ausfällen in einem Unfall enden kann. Deswegen sollen interne Ausfälle gemeldet und so schnell wie möglich repariert werden, oder Wartungsuntersuchungen müssen regelmäßig so oft durchgeführt werden, daß die Wahrscheinlichkeit für mehrere Ausfälle zwischen zwei Wartungen extrem niedrig ist. Deswegen soll ein sicheres System nicht nur einen, sondern mehrere gleichzeitige interne Ausfälle garantiert tolerieren können.
Umgang mit Sensoren
Die Steuerung kann nicht besser sein als die von den Sensoren gelieferten Informationen. Mit falschen Daten werden auch falsche Handlungen unternommen. Man muß sich bewußt sein, daß die Daten aus den Sensoren nicht einmal im normalen Betrieb genau der Realität entsprechen. Zunächst einmal wird nicht die gesamte Anlage durch Sensoren erfaßt, viele Stellen bleiben für die Steuerung unsichtbar und ihr Zustand wird einfach durch Berechnungen aus anderen gemessenen Daten vermutet. Dafür muß (meistens unbewußt) ein mathematisches Modell der Anlage in der Steuerung programmiert sein. Da diese Werte aufgrund von (unbewußten) Annahmen des Entwicklers berechnet werden, bilden sie eine große Quelle von Fehlern. Auch die gemessenen Werte basieren auf Annahmen des physikalischen Verhaltens; z.B. wird die Temperatur in einem Temperatursensor aus dem Strom, der durch die Meßprobe geht, berechnet. So werden die physikalischen Größen zu elektrischen Signalen, dann zu Daten, und dann durch Interpretationen (Modell + Annahmen) zu Informationen umgewandelt, und erst dann werden sie von der Steuerung benutzbar. Neben der Fehlerquelle Modellbildung (ideale, vereinfachte Anlage) gibt es noch zwei Ungenauigkeitsquellen (Abbildung 1):
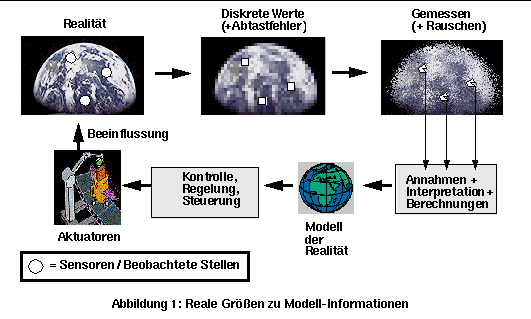
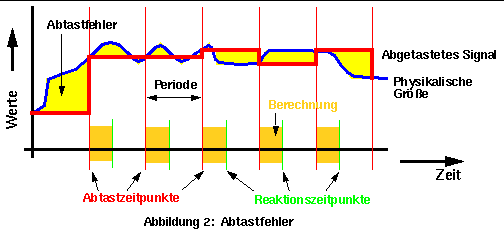
1. Die notwendige Diskretisierung für die digitale Verarbeitung ergibt einen Abtastfehler. Die gemessenen Werte am Anfang eines Steuerungszyklus werden als konstant für den ganzen Zyklus angenommen (Abildung 2).
2. Das Meßverfahren selbst hat ein gewisses Rauschen, das sich innerhalb der Meßtoleranz bewegen muß. Der Fehler kann Random oder meßbedingt sein wie z.B. aufgrund der Trägheit des Meßinstruments. In jedem Fall kann der gemessene Wert nicht als genauer Punktwert betrachtet werden, sondern vielmehr als ein Plausibilitätsbereich (Wert +- Toleranz = [Wert-Toleranz .. Wert+Toleranz]), in dem sich die reale Größe befinden muß (Abbildung 3). Dieser Bereich ist meistens klein genug (+/-5%), so daß er als ein Punkt behandelt werden kann.
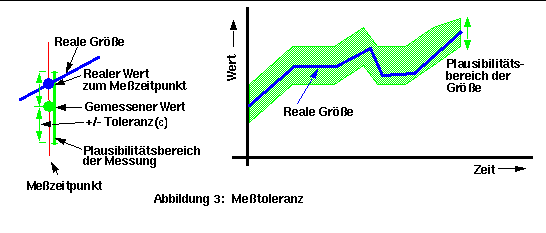
Wenn man die Meßdaten als Bereich und nicht als Punkt betrachtet, kann die Steuerung sicherer sein und ein Meßinstrumentenausfall kann mit demselben Code wie im normalen Fall behandelt werden.
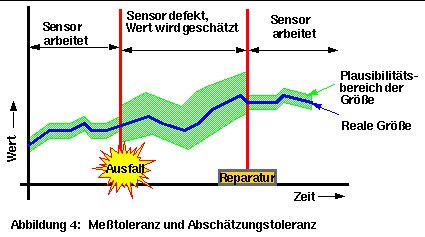
Beispielsweise hat ein Automobil-Geschwindigkeitssensor eine Toleranz von 10%. Beim Ausfall des Geschwindigkeitssensors kann die Geschwindigkeit aus Strecke und Zeit abgeleitet werden. Die Toleranz beträgt in diesem Fall aber mehr als 10% (Toleranz des Streckensensors + Toleranz des Zeitmessers + andere Faktoren). Wenn die Steuerung für die Bearbeitung von Bereichen konzipiert ist, braucht sie nicht einmal zu wissen, daß der Geschwindigkeitssensor ausgefallen ist. Sie bekommt einfach einen breiteren Plausibilitätsbereich zu bearbeiten. Durch diese Berechnungsmethode braucht man keinen extra Code zu schreiben, um diese Ausnahme zu behandeln. Dies ist besonders wichtig, wenn die Steuerung mit Daten aus vielen Sensoren arbeitet. In diesen Fällen wäre es nicht praktikabel, für jeden Fall von Sensorausfall und für alle Kombinationen von Ausfällen (Tausende oder gar Millionen von Kombinationen) jeweils einen extra Code zu schreiben. Statt dessen braucht man nur schmalere oder breitere Bereiche als Eingabewerte mit demselben Code zu behandeln (Abbildung 4).
Bei der Abschätzung einer Größe mittels indirekter Redundanz kann der Plausibilitätsbereich mit der Zeit wachsen und damit wird die Genauigkeit der Steuerung schlechter. Dies ist der Fall, wenn die Abschätzung mittels Akkumulation oder Integration erfolgt, bzw. wenn der letzte Wert benutzt wird, um den nächsten zu berechnen (Abbildung 5).
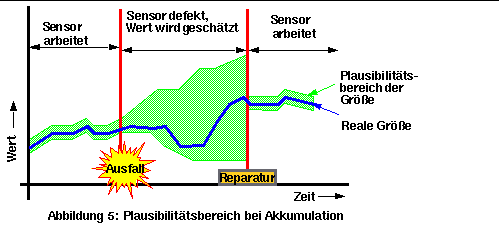
Beispielsweise wird bei der Abschätzung der Geschwindigkeit (v) aus Beschleunigung (a) und Zeit (t): v = v + a*t das neue v den Fehler des alten v haben plus den neuen Fehler aus a*t. Nach einigen Zyklen kann damit der Bereich so breit sein, daß die Steuerung handlungsunfähig wird. Dieses Problem hat man nicht, wenn die Abschätzung mittels Ableitung ohne Akkumulation geht, z.B.: v = s/t. (s = Strecke).
Die Wichtigkeit der Nutzung des gesamten Bereichs in den Berechnungen und nicht nur des Mittelwerts wird in folgendem Beispiel gezeigt. Es handelt sich um einen Temperatursensor mit einer Toleranz von 10%. Die Anlage muß spätestens, wenn die Temperatur die MAX-Grenze erreicht hat, abgeschaltet werden:
if(temp >= MAX) emergency(); // es könnte bereits zu spät sein
if(temp * 1.10 >= MAX) emergency(); // auf der sicheren Seite
Als Beispiel für eine Steuerung mit Plausibilitätsbereichen kann ein Wasserkessel dienen. Die Aufgabe ist, die Wassermenge zwischen 4000 und 5000 Litern zu halten und bei MAX muß alles abgeschaltet werden. Dafür kann man eine Pumpe ein- und ausschalten und ein Entleerungsventil auf- und zudrehen. Die Steuerungsfunktion auf konventionelle Art in ihrer einfachsten Form würde so aussehen:
if(Inhalt > 5000) VentilAuf();
if(Inhalt < 4800) VentilZu(); // 4800 basiert auf unbegründeten Annahmen
if(Inhalt > 4300) PumpeAus(); // 4300 basiert auf unbegründeten Annahmen
if(Inhalt*1.10 >= MAX) Notaus(); // 10% Toleranz wird angenommen
Dieselbe Steuerung mit Plausibilitätsbereichen ist in der Abbildung 6 dargestellt.
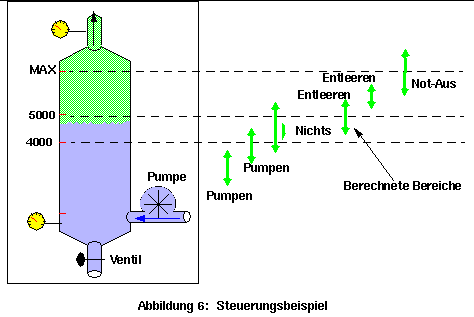
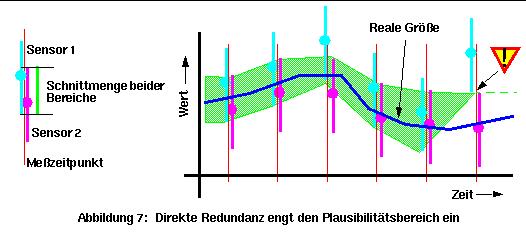
Je schmaler die Bereiche sind, desto genauer kann die Steuerung arbeiten. Unter Verwendung der indirekten und der direkten Redundanz kann die Qualität der Informationen folgendermaßen verbessert werden: Bei der direkten Redundanz wird die Schnittmenge der Plausibilitätsbereiche der Messungen der verschiedenen Sensoren gebildet:

Dieser schmalere Bereich ist dann der neue Plausibilitätsbereich. Wenn die Schnittmenge Null ist, liegen die Meßdaten außerhalb der Toleranz und mindestens eine der Messungen ist falsch. Durch die Plausibilitätsbereiche werden die redundanten Werte effektiver genutzt und das Problem des Vergleichs der Meßwerte ist damit auch gelöst (Abbildung 7).
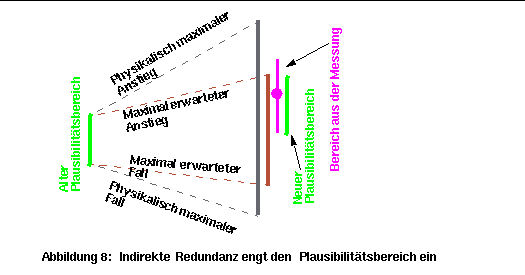
Durch die Verwendung von indirekter Redundanz kann man vom letzten Plausibilitätsbereich ausgehen und den neuen berechnen. Dafür können die physikalischen Grenzen, das durch die Stellgrößen erwartete Verhalten des Systems und die indirekte Redundanz aus anderen Sensoren benutzt werden. Die Schnittmenge von allen diesen Bereichen ergibt den neuen Plausibilitätsbereich (Abbildung 8).
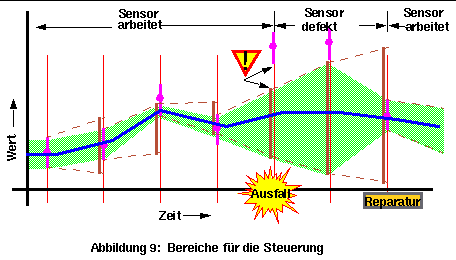
Falls keine Sensorwerte zur Verfügung stehen (z.B. bei einem Ausfall), kann dieser Bereich für die Steuerung benutzt werden. Sonst kann man wiederum die Schnittmenge dieses Bereichs mit dem Plausibilitätsbereich aus den Sensoren bilden, um die Meßdaten zu prüfen und die Qualität der Steuerungsdaten noch weiter zu verbessern (Abbildung 9). Falls die Schnittmenge Null ist, haben wir ein weiteres Problem: Etwas stimmt nicht. Man muß nur herausfinden, was falsch ist (applikationsabhängig).
Die Sensoren, die nur binäre Werte (ja/nein, True/False) liefern, können nicht mit Plausibilitätsbereichen behandelt werden. Hier muß man andere Plausibilitätsprüfungen (applikationsabhänging) durchführen. Beispiel: Ein Sensor meldet "Ventil auf" und ein anderer "Ventil zu". Wenn beide gleichzeitig aktiv sind, dann stimmt etwas nicht.
Umgang mit Aktuatoren
Anders als bei den Sensoren kann man die Aktuatoren nicht direkt beobachten, sondern nur indirekt durch die Sensoren. Das sicherste ist es, mit jedem Aktuator einen Sensor zu assoziieren, um seine Aktionen auf dem direktesten Weg zu beobachten. Im Fall von verdächtigem Verhalten weiß man dann aber nicht, ob der Aktuator oder der Sensor defekt ist. Um den Fehler einzugrenzen, muß man weitere Redundanz, wie z.B. die indirekte, benutzen. Wenn Aktuatoren nicht direkt durch dedizierte Sensoren beobachtet werden, können ihre Aktionen nur von der Reaktion des gesamten Systems abgeleitet werden. Dies wird von anderen Sensoren ermittelt und durch Berechnungen und Annahmen kann die Stellung eines bestimmten Aktuators geschätzt werden. Dies bewirkt, daß mögliche Fehlererkennung viel später und unsicherer stattfindet, denn das Gesamtsystem ist viel träger als der Aktuator. Wenn z.B. das Ruder eines großen Schiffes klemmt, könnte es sehr schnell an der Ruderposition erkannt werden. Wenn das nicht möglich ist, weil es keinen Sensor am Ruder gibt, kann man den Fehler erst ein paar Minuten später erkennen, wenn man bemerkt, daß das Schiff auf Lenkbefehle nicht reagiert. Unter Umständen könnte dann die Fehlererkennung zu spät stattfinden. Weiterhin wird die Fehlerlokalisierung schwieriger, z.B. klemmt das Ruder oder wird das Schiff von einer Wasserströmung in eine andere Richtung bewegt? In diesen Fällen kann man nicht so einfach wissen, warum das System sich anders verhält als erwartet. Das Schlimmste ist, wenn die Aktionen eines Aktuators von keinem Sensor, weder direkt noch indirekt, registriert werden können. Dies kann sehr leicht zu Unfällen führen. Beispiel: Eine (hypothetische) Ampelsteuerung kann den (realen) Zustand der Lampen nicht beobachten. Wenn dann die rote Lampe bei der Vorfahrtstraße nicht leuchtet (defekt) und die Steuerung nichts davon weiß, kann dies sehr leicht zur Ursache von Unfällen werden. Wenn die Steuerung es jedoch merken würde, könnte sie entweder die gesamte Anlage ausschalten oder aber den anderen Straßen Blink-Gelb zeigen, nur auf keinen Fall Grün.
Weiterhin erlaubt eine direkte Beobachtung der Aktuatoren ihre Rekalibrierung im Betrieb (online). Beispiel: Ein Roboterarm leiert mit der Zeit aus. Seine Stellung wird bei den gleichen Stellwerten nicht die gleiche wie am Anfang sein. Außerdem ist die Stellung auch temperaturabhängig. Dadurch ist eine direkte Beobachtung bei Präzisionsarbeiten ohnehin unerläßlich. Eine direkte Beobachtung ist auch unerläßlich, wenn es für den Aktuator verbotene Bereiche gibt, wie z.B. andere Teile oder Personen, die der Roboterarm nicht anstoßen darf. Statische verbotene Bereiche können einfach und sicher durch mechanische Sperrungen gesichert werden. In dynamischen Bereichen (z.B. andere sich bewegende Teile) muß die Anlage per Software (flexibler, aber auch unsicherer) gesichert werden. Dies impliziert eine direkte Beobachtung des Aktuators.
Aus Fehlertoleranzgründen können mehrere Aktuatoren direkt redundant sein (identische Funktion). Sie können zusammen gesteuert werden, um eine kräftigere und schnellere Reaktion im System zu erreichen, wie z.B. die Stellflächen von Flugzeugen. In diesem Fall bewirkt ein Ausfall eine schwächere Reaktion des Systems, die allerdings genügen sollte, das System sicher steuern zu können. Problematisch wird es, wenn der ausgefallene Aktuator in einer nicht neutralen Stellung klemmt und z.B. in die Gegenrichtung "lenkt". Dies kann die Steuerbarkeit des Systems beeinträchtigen. Man muß die ausgefallenen Aktuatoren so weit wie möglich aus der Kontrollschleife entfernen und deaktivieren, damit sie nicht ungewollt das System beeinflussen (siehe unten). Ohne eine direkte Beobachtung jedes parallel geschalteten Aktuators ist es schwierig festzustellen, welcher Aktuator defekt ist. Man erkennt nur, daß die Reaktion des Systems den Erwartungen nicht entspricht. Man muß im Betrieb jeden einzelnen Aktuator getrennt ansteuern und das Systemverhalten beobachten um zu erkennen, welcher der defekte ist. Aber dies ist eine riskante Operation, die nicht zur normalen Funktion des Systems gehört. Nach Möglichkeit sollte sie unter Aufsicht oder sogar unter der Kontrolle des Operators durchgeführt werden.
Wenn das System nicht dafür ausgelegt ist, den Ausfall eines redundanten Aktuators zu erkennen, kann das gesamte System nach einem Ausfall in einen latenten Ausfallzustand geraten (latente Gefahr). Nach dem ersten Ausfall ist das System - ohne es zu merken - nicht mehr fehlertolerant. Ein zweiter Ausfall würde das System unsteuerbar machen, es sei denn, man kann noch eine indirekte Redundanz einsetzen. Um diese Situation zu vermeiden, sollen die Aktuatoren ständig direkt beobachtet werden. Ist das nicht möglich, soll die Steuerung sie so oft wie möglich getrennt ansteuern und testen. Bei den Systemen, wo redundante Aktuatoren zusammen angesteuert werden (beide aktiv), müssen bei Ausfällen die Betriebsparameter des Systems geändert werden, um die Sicherheit garantieren zu können. Beispiel: Beim Ausfall einer der beiden Bremskreise in einem Auto steht dann nur die Hälfte der Bremskraft zur Verfügung. Daher soll die maximale sichere Geschwindigkeit entsprechend heruntergesetzt werden. Bei einem Fahrzeug mit mehreren Antriebsmotoren bewirkt ein Ausfall, daß weniger Kraft zur Verfügung steht. Dies muß bei Steigungen berücksichtigt werden, um einschätzen zu können, ob die vorhandene Kraft noch ausreicht, die Steigung zu überwinden. Eine Fehleinschätzung könnte also zur Überlastung der restlichen Motoren führen und weitere Ausfälle verursachen.
Eine andere Möglichkeit für den Einsatz direkt redundanter Aktuatoren ist, nur einen aktiv (Primär) und den anderen als passive Reserve (Schatten) zu benutzen. Jeder Aktuator muß stark genug sein, um allein das System wie erwartet zu beeinflussen. Dadurch sind die Aktuatoren überdimensioniert und die Mittel werden nicht optimal eingesetzt. Auf der anderen Seite bringt diese Überdimensionierung die nötige Sicherheit für den Fall eines Ausfalls. Falls der aktive Aktuator ausfällt, wird das System umkonfiguriert, d. h. der passive Aktuator wird aktiviert und übernimmt die Aufgabe. Hier hat man wieder das obengenannte Problem, daß man einen eventuellen Ausfall des passiven Aktuators nicht erkennen würde (latenter Ausfallzustand), bis man ihn braucht. Dann jedoch wäre es zu spät. Bei diesen Systemen sollte man die Rollen von primären und Schattenaktuatoren möglichst immer wieder umtauschen, um beide Aktuatoren im normalen Betrieb zu testen.
Der Ausfall eines Aktuators kann, wie bereits erläutert, erkannt werden. Seine Behandlung ist aber schwieriger als bei den Sensoren oder Prozessormodulen. Defekte Sensoren kann man einfach ignorieren. Defekte Prozessoren und andere aktive Elemente kann man ausschalten, damit sie nicht andere Module stören. Defekte Aktuatoren sind problematischer. Sie befinden sich physikalisch im System und wir können sie (in der Regel) nicht verschwinden lassen. Sie beeinflussen es, ob wir es wollen oder nicht; z.B. kann man eine Bremse, die in geschlossenem Zustand klemmt, nicht einfach ignorieren oder den Fehler per Software und Rekonfiguration beheben. Ein Entleerungsventil, das in offener Stellung klemmt, kann einen Systemausfall verursachen. In einer Ampelanlage kann eine grüne Lampe, die sich nicht ausschalten läßt, große Verwirrung verursachen. Im Vergleich dazu können die invertierten Probleme - eine Bremse im offenen Zustand, ein Entleerungsventil in geschlossener Stellung und eine durchgebrannte Lampe - sehr einfach durch direkte Redundanz beseitigt werden. Es können aber auch beide Situationen zugleich auftreten.
Das Problem der unerwünschten Beeinflussung durch defekte Aktuatoren kann man nicht vollständig eliminieren. Man kann nur seine Wahrscheinlichkeit extrem niedrig halten, bzw. in einigen Fällen dieser Beeinflussung durch den Einsatz zusätzlicher Aktuatoren entgegenwirken. Das erste wird erreicht, indem Aktuatoren mit einer definierten Ausfallstellung (oder Ausfallposition) benutzt werden. Dies wird durch mechanische Konstruktionen, wie z.B. interne kräftige Federn, realisiert. Beispiel: Eine Ventilsorte, die sich bei einem Ausfall "immer" schließt, oder eine andere Sorte, die sich bei einem Ausfall "immer" öffnet. Wobei "immer" relativiert werden muß, denn alles ist möglich. Ein anderes Beispiel: Die alten mechanischen Eisenbahnsignale waren so konstruiert, daß, wenn das Steuerungskabel brach, sie durch die immer geltende Schwerkraft in die "Halt"-Position fielen. Man kann auch durch andere Aktuatoren entgegenwirken. Die physikalische Konfiguration (parallel oder seriell) von direkt redundanten Aktuatoren muß entsprechend ihrer Ausfallposition gewählt werden, so daß die Wirkung des Ausfalls eines Aktuators durch die Wirkung eines zweiten eliminiert werden kann (Abbildung 10).
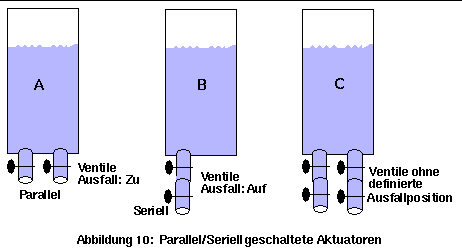
Nebenbei kann man auch für den Fall, daß beide Aktuatoren ausfallen, einen sicheren Systemausfall vorbereiten. Beispiel: Wenn es sicherer wäre, den Wassertank der Abbildung 10 im Notfall zu entleeren, dann sollten Ventile mit der Ausfallposition "Auf" eingesetzt und seriell geschaltet werden. Falls dann beide Ventile ausfielen, würde der Wassertank entleert, ohne daß die Steuerung es beeinflussen könnte. Die gleiche Sicherheit beim Systemausfall (Fail safe) wird bei der Verwendung von Aktuatoren mit definierter Ausfallposition angestrebt, auch wenn keine direkt redundanten Aktuatoren benutzt werden.
Wenn die Aktuatoren keine definierte Ausfallposition haben, oder wenn die (niedrige aber existente) Wahrscheinlichkeit, daß sie in der unsicheren Stellung klemmen, noch stets ein unvertretbar hohes Risiko darstellt, muß jeder Aktuator doppelt gesichert und die gesamte Konstruktion redundant (4-fache Redundanz) gestaltet werden, wie die Abbildung 10,C zeigt.
Weitere Referenzen
Mein Buch: Sichere und Fehlertolerante Steuerungen

[FTCS-28]:
Annual international Symposium on Fault-Tolerant Computing
http://www.chillarege.com/ftc
Fehlertolerante Architekturen, Transaktionen, Verteilte und Echtzeit-Verbindungsnetzwerke, Software und in VLSI.
./seminar
Seminar an der Technischen Universität Berlin über Sicherheit,
Hazard-Analyse, Fehlertoleranz, Analysen von Unfällen und Entwicklung sicherheitsrelevanter eingebetteter Systeme.
[Hazard Analyse]
./public
->Analysen der Anlagen-Sicherheit und Gefahren (Hazard-Analyse)
Gefahr, Fehler und Unfälle, Vorwärts- und Rückwärts-Suche,Top-Down und Bottom-Up Suche, Sammeln und Protokollieren von Informationen, Checklisten, Ereignisbaumanalyse (ETA: "Event-tree-analysis"), Fehlerbaumanalyse (FTA: "Fault-tree-analysis"), Ursache-Wirkungs-Analyse (CCA / CEA: "Cause-Effect-analysis"), Ausfallarten- und Wirkungs-Analyse (FMAE: "Failure modes and effects")
[konzeption]
./public
->Konzeption sicherheitsrelevanter eingebetteter Systeme
Vereinfachen, Kooperation Mensch-Maschine, Risiken und Gefahren erkennen, Gefahren beherrschen
---------------------------------------------------------------------------------------------
Sergio Montenegro
GMD-FIRST,
Rudower Chaussee 5,
D-12489 Berlin-Adlershof
Tel +49/30/6392-1878,
email: sergio@first.fhg.de