S. Montenegro (.)
GMD-FIRST (http://www.first.fhg.de)
(2.1)
Sichere und fehlertolerante Systeme werden dort benötigt, wo ein Ausfall tödliche Folgen haben (sicherheitskritische Anwendungen) oder große Verluste verursachen kann. Solche Systeme müssen trotz interner Fehler und Ausfälle weiterlaufen. Sie müssen sich vor fehlerhaften Inputs und unerwarteten Umständen in ihrer Umwelt schützen (robust sein), um weiterlaufen zu können.
Stellen Sie sich vor, Sie haben ein vollkommen fehlertolerantes und robustes System entwickelt - eine Lokomotive. Kein interner Fehler, keine äußeren Umstände können sie stoppen. Leider hat ihr System einen Entwicklungsfehler und es macht nicht das, was es soll, sondern etwas anderes, dafür aber ganz sicher, und man kann es nicht mehr anhalten. Ein sicheres System mit Entwicklungsfehler wird mit Sicherheit gefährlich sein. Deswegen sollte der erste Schritt bei der Konstruktion von sicherheitsrelevanten Systemen eine korrekte Entwicklung sein, so daß das System tut, was es tun soll und nichts anderes.
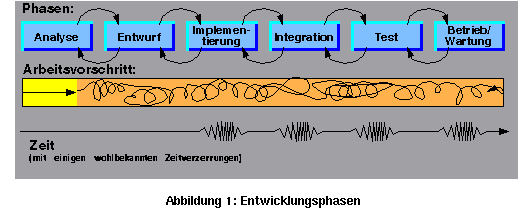
Während man Laufzeitfehler durch Redundanz und Fehlertoleranz-Techniken halbwegs in den Griff bekommen kann, bleiben die Entwicklungsfehler ein offenes Problem. Entwicklungsfehler können zu den verschiedensten Zeitpunkten und Phasen im Verlauf des Entwicklungsprozesses entstehen. Die (Standard) Phasen und ihre Probleme werden in Abbildung 1 dargestellt. Hier wird nicht versucht, ein Vorgehensmodell einzuführen, es werden einfach Einzelheiten erwähnt, an die Sie in den verschiedenen Entwicklungsphasen denken sollten.
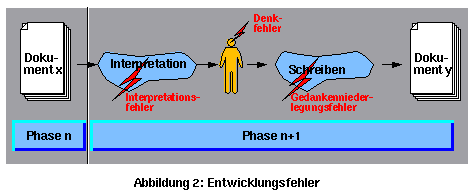
In jedem Schritt von einer Phase in die nächste entstehen Fehler aus drei Kategorien (Abbildung 2): Interpretations-, Denk- und Gedankenniederlegungsfehler. Je mehr Phasen die Entwicklung hat, um so mehr Fehler werden sich akkumulieren.
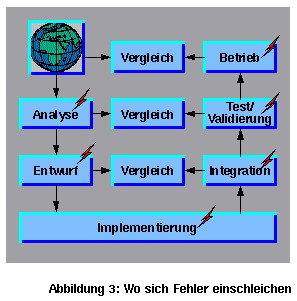
Bei jedem Entwicklungsschritt können sich Fehler einschleichen, deswegen muß jede Komponente gegen ihre Anforderungen systematisch (und vollständig) getestet werden (Abbildung 3). Bei der Integration werden einige Programmfehler gefunden. Dies sind die Sachen, an die der Programmierer nicht gedacht hat. Bei Systemtest und Validierung werden einige Entwurfs- und Analysefehler gefunden. Das sind die, die der Analytiker nicht gesehen hat. Und im Betrieb werden die meisten Fehler gefunden. Dies sind solche Sachen, die keiner wußte und an die keiner dachte, nicht einmal der Kunde oder Endbenutzer selbst. Beispiel: Ein Kraftfahrzeugfabrikant gibt einen erweiterten Tempomat in Auftrag, der die Geschwindigkeit des vorausfahrenden Fahrzeugs messen und damit die eigene Geschwindigkeit begrenzen soll. In der Testphase funktioniert er gut, aber im normalen Betrieb bremst der Tempomat am Ende eines Überholvorgangs, wenn plötzlich ein anderes Fahrzeug entgegenkommt.
Eine hohe Entwicklungsqualität und damit eine niedrige Fehlerrate kann durch folgende allgemeine Maßnahmen erreicht werden:
-
Einfachheit und Überschaubarkeit [einfach] (das wichtigste)
-
umfassende Spezifikation der Systemanforderungen
-
umfassende Kenntnis der Systemumgebung [pendel]
-
Erstellung von Prototypen
-
Gründliche Simulation
-
Gebrauch von bewährten Entwicklungsmethoden und Werkzeugen
-
Anwendung von formalen Methoden [Formale Methoden],
Validierung und Verifikationstechniken
-
Fehlerprotokolle (s. 1.)
-
Projekthistorie führen (s. 2.)
-
Tracebility in der gesamten Entwicklung (s. 3.)
-
Entwicklung-Reviews (s. 4.)
1. Menschliche Fehler sind repetitiv, ihre Muster wiederholen sich immer wieder. Deswegen ist es eine Hilfe, Ihre eigenen Fehler zu protokollieren und zu klassifizieren. Dann können Sie bei neuen Entwicklungen nach Ihrem eigenen Fehlermuster suchen und dadurch eine Fehlerwiederholung vermeiden und mehr als 50% der Entwicklungsfehler frühzeitig korrigieren.
2. Der Entwicklungsprozeß erfordert viele Entscheidungen der Entwickler. Getroffene Entscheidungen müssen nachvollziehbar sein. Man muß festhalten, warum eine Entscheidung einer anderen vorzuziehen ist. Auch falsche Entscheidungen, Sackgassen, Probleme und Mißerfolge müssen protokolliert werden (Projekthistorie).
3. Der technische Anfang der Entwicklung sind die Anforderungen an das System. Diese Anforderungen müssen über die gesamte Entwicklung nachvollziehbar sein (Tracebility). Man muß protokollieren, welche Anforderungen in welchen Modulen implementiert werden und wo sie getestet werden. Dies ist eine Hilfe, um Anforderungen nicht zu übersehen und um die Nebenwirkungen von Änderungen zu ermitteln. Wenn möglich, sollte man eine durchgängige Strukturierung von den Systemanforderungen hin bis zum Code anstreben.
4. Fremde Inspektionen (Audits, Reviews) verbessern die Entwicklungsqualität. Allein durch die Vorstellung, daß Sie Ihr Design, Code oder Hardware jemandem zeigen und erklären müssen, werden Sie viel ordentlicher und aufmerksamer entwickeln. Bei der Erklärung Ihrer Arbeit werden Sie selbst Details (und eventuell Fehler) erkennen, die Ihnen beim Entwickeln nicht gegenwärtig waren.
Analyse bedeutet "auflösen". Aber was man braucht, ist eine gesamte Sicht des Systems und nicht nur der einzelnen Teile. Die daraus entstehende (System-) Spezifikation sollte folgendes berücksichtigen:
-
Sprache des Anwenders benutzen(s. 1.)
-
Bestimmung und Zweck des Systems (s. 2.)
-
Abgrenzung des Systems (s. 3.)
-
Annahmen (s. 4.)
-
Beschreibung des physischen Systems und Umgebung (s. 5.)
-
Funktionsanforderungen (s. 5.)
-
Sicherheitsanforderungen (s. 5.)
1. Die Sprache des Anwenders soll benutzt und gelernt werden, ohne zu versuchen, dem Anwender unseren Informatik- bzw. Elektrotechnik-Slang aufzuzwingen. Die Beschreibung muß sich so nah wie möglich an die informelle Beschreibung des Anwenders halten. Eine fachgebietsorientierte Spezifikation minimiert die Übersetzungsfehler. Bezeichner sollten so deskriptiv wie möglich gewählt werden und auf Abkürzungen sollte weitestgehend verzichtet werden. Vor allem soll die Spezifikation so verständlich und kurz (handlich) wie möglich sein, sonst hilft alles andere nichts. Und gerade dieser extrem wichtige Punkt wird zu oft mißachtet (siehe z.B. die OSI Standards).
2. Die Spezifikation beschreibt nicht nur "Was" sonder auch "Wofür" das System ist. Dies erleichtert das Verständnis des Systems und des Zusammenwirkens seiner Komponenten. Der Entwickler muß wissen, wofür das System gebaut wird und nicht nur, was gebaut werden soll. Dadurch kann er auch Spezifikationslücken beim Entwickeln entdecken.
3. Für eingebettete Systeme muß immer eine Grenze zwischen System und Umgebung gezogen werden. Das System können wir gestalten und es soll definierte Schnittstellen zu seiner Umgebung haben. Weiterhin stellt auch die Umgebung bestimmte Anforderungen an unser System.
4. Es ist hilfreich, alle Annahmen über Gesamtsystem und Umgebung festzuhalten. Leider kann der Entwickler meistens zwischen Annahmen und Tatsachen nicht unterscheiden. Oft ist ihm nicht einmal bewußt, daß er nur auf Annahmen baut. Sind die Annahmen falsch, so fällt damit alles zusammen. Deswegen müssen die Annahmen so weit wie möglich als solche identifiziert werden, damit ihre Richtigkeit während des Entwicklungsprozesses geprüft werden kann. Sonst wird ihre Richtigkeit nicht in Frage gestellt und Fehler, die auf falschen "Tatsachen" beruhen, werden in der gesamten Entwicklung und auch beim Testen nicht entdeckt (man testet, was man angenommen hat), sondern fallen irgendwann in der Anwendungsphase unangenehm auf. Dies ist das schlimmste.
Beispiel: In Tiefflügen bewährte amerikanische Flugzeuge wurden von Israel gekauft und auch über dem Toten Meer eingesetzt, mit dem Ergebnis, daß sie fast abgestürzt wären. Das Tote Meer liegt unterhalb des Meeresspiegels und das System zur Bestimmung der Flughöhe wurde niemals unter diesen Bedingungen getestet. Die Tatsache", daß ein Flugzeug immer oberhalb Normalnull fliegt, erwies sich als falsche Annahme. Hätten Sie daran gedacht, daß ein Flugzeug unter dem Meeresspiegel fliegen könnte?
5. Durch das Aufteilen von Spezifikation und Anforderungen in 1. Umgebung, 2. Funktionsanforderungen und 3. Sicherheitsanforderungen wird eine bessere Verständlichkeit und damit eine höhere Sicherheit erreicht. Manchmal ist es sogar möglich, die Anforderungen weiter zu unterteilen:
-
Umgebung
-
Funktion
-
Sicherheit
-
Echtzeit
-
Leistung
-
Fehlertoleranz
-
Kommunikation
-
Struktur
-
u.a.
Die Umgebungsbeschreibung enthält die physikalischen Eigenschaften, Schnittstellen zwischen Umgebung und System, Annahmen und Tatsachen zur Umgebung, Unterstellungen über den Betrieb, Terminologien und Begriffsdefinitionen.
Die Funktionsanforderungen beschreiben, was das System machen soll: wofür das System gebraucht wird oder wofür es gebaut wird. Die Sicherheitsanforderungen beschreiben alle Gefahren und alles was niemals geschehen darf. Zuerst werden die Funktionsanforderungen im normalen Betrieb und die dabei entstehenden ersten Sicherheitsanforderungen betrachtet und getrennt festgehalten. Danach werden die Anforderungen im realitätsnäheren Fall, unter Berücksichtigung von Störungen, Ausfällen, Fehlern, Fehlbedingungen usw. untersucht und wiederum getrennt Funktion/Sicherheit erfaßt. Anschließend beschreiben Sie was zu tun ist, wenn nichts mehr geht! Dieser Fall wird mit Sicherheit auch eintreten.
Die gesamten Funktionsanforderungen eines Systems sind wesentlich komplexer als seine Sicherheitsanforderungen und deswegen sind mehr Fehler bei der Funktion als bei der Sicherheit zu erwarten. Wenn wir die Sicherheitsaspekte abtrennen, können wir uns gezielter auf die Sicherheit konzentrieren, ohne viele irrelevante Aspekte mit berücksichtigen zu müssen. Bei der Spezifikation des Systems sollte eine explizite Trennung funktionaler und sicherheitsrelevanter Bestandteile erfolgen. Nach Möglichkeit sollten beide Spezifikationen sogar von verschiedenen Entwicklern gemacht werden. Die sicherheitsrelevanten Teile sollten so klein und einfach wie möglich und frei von für die Sicherheit irrelevanten Teilen gehalten werden.
Die Spezifikation kann mit zwei verschiedenen Stilen, die nicht gemischt werden sollten, geschrieben werden: operational und axiomatisch. In einer operationalen Spezifikation passiert nur das, was explizit spezifiziert wurde, wie in einer imperativen Programmiersprache. In einer axiomatischen Spezifikation kann alles eintreten, was nicht explizit ausgeschlossen wurde. Eine operationale Spezifikation beschreibt die Funktion des Systems, während eine axiomatische Spezifikation die Eigenschaften beschreibt. Ein Teil einer operationalen Spezifikation könnte z.B. sagen: "Wenn die Temperatur zu hoch ist, schalte die Flamme aus!". In einer axiomatischen Spezifikation würde es so lauten: "Immer wenn die Temperatur zu hoch ist, soll die Flamme aus sein.".
Einige Techniken sind eindeutig axiomatisch und andere operational. Z.B. Timing Diagrams sind axiomatisch. Sie beschreiben, welche Zeitanforderungen erfüllt werden müssen, aber sie sagen nicht, was zu tun ist. Programmiersprachen, Statecharts u.a. sind operational. Sie sagen was getan werden muß, aber nicht welche Randbedingungen einzuhalten sind. Problematisch wird es, wenn eine Technik für beide (axiomatisch und operational) benutzt werden kann (natürliche Sprache, Z, VDM, CSP). Eine Vermischung produziert nur Konfusionen. Bei jeder Aussage hat man die Frage: Handelt es sich hierbei um Axiome, um das zulässige Verhalten des Systems einzuschränken? Oder handelt es sich um Operationen, die durchgeführt werden sollen? Gefährlich wird es, wenn beide Formen unkontrolliert gemischt werden.
Eine operationale Spezifikation ist vollständig, wenn alle Funktionen und Operationen spezifiziert sind. Eine axiomatische Spezifikation ist vollständig, wenn jedes unerwünschte Verhalten ausgeschlossen ist. Beide Teile sind konsistent zueinander, wenn die axiomatische Spezifikation die Aktionen der operationalen Spezifikation zuläßt. Sonst kann eine Spezifikation nicht implementiert werden, weil es unmöglich ist, ihre Anforderungen zu erfüllen.
Wenn alle" Anforderungen formuliert sind, wird das System in Module aufgeteilt (Entwurf). Dabei werden die Anforderungen auf die Module verteilt, die Schnittstellen und das Zusammenspiel der Module werden definiert. Die Funktionsanforderungen können relativ einfach auf die Module verteilt werden. Die Sicherheitsanforderungen aber nicht. Sie gelten nur für das gesamte System. In diesem Prozeß müssen neue Sicherheitsanforderungen für jedes Modul formuliert werden.
Die Modularisierung ist nötig, um die Komplexität beherrschen zu können. Die Entwicklungsfehlerrate, Entwicklungszeit und Kosten wachsen schneller als die Komplexität, und die Komplexität wächst viel schneller als die Anzahl der Programm LOC (Lines of code), der Gatter und Hardwarekomponenten. Deswegen ist die Modularisierung die beste Maßnahme gegen das exponentielle Wachstum der Probleme. Weiterhin ist der erste Feind der Sicherheit die Komplexität. Wenn die Komplexität eines Systems steigt, sinken seine Sicherheit und seine Verläßlichkeit, und die Entwicklung wird unübersichtlicher. Hinzu kommt, daß man bei einer modularen Anwendung einen Teil der Anlage herunterfahren und ersetzen/reparieren kann, ohne die gesamte Anlage abschalten zu müssen.
Aber Vorsicht: Die größte Schwachstelle bei jeder Entwicklung kommt aus dem Entwurf der Schnittstellen. Dort werden die meisten Fehler gemacht. Der Grund dafür sind Fehlinterpretationen und schlechte Dokumentation. Schnittstellen sollen genau und mit Beispielen dokumentiert werden. Bei Software sollen die Beispiele mit Cut-and-Paste übernommen werden. Bei Hardware sollen die Schnittstellen besonders aufmerksam simuliert werden. Beispiel: Beim Entwickeln zweier Hardware-Module definierten, simulierten und verifizierten wir besonders aufmerksam die Schnittstelle zwischen den beiden. Die Module wurden von verschiedenen Personen getrennt entwickelt. Beide implementierten die Schnittstelle haargenau gleich, auch den Stecker - zweimal Buchsen (Mutter) -, so daß wir die Module nicht zusammenstecken konnten.
Jede Komponente hat eine geplante Interaktion mit ihrer Umgebung, aber oft genug wird vergessen, daß es auch eine ungeplante und unerwünschte Interaktion gibt, wie thermische Einflüsse (z.B. Winter/Sommer, interne Wärmequellen), Vibrationen, Strahlungen, Elektromagnetismus (z.B. durch Starkstrom), chemische Reaktionen u.a. Besonders bei Steuerungen und eingebetteten Systemen sind die externen und die internen unerwünschten Einflüsse extrem hoch. Das Einschalten von Motoren erzeugt starke elektromagnetische Wellen, die Steuerung für einen Backofen oder ein Bügeleisen wird sehr warm werden usw. Man kann die ungeplanten Interaktionen mit Abschirmung, Schutzeinrichtungen u.a. begrenzen, aber nicht ausschalten. Besonders deshalb nicht, weil wir sie nicht alle im voraus kennen. Deswegen muß das System immer für das Unerwartete und Unvorhersehbare vorbereitet sein. Beispiel: An einer Autobahn steht ein Sendemast. Einige Fahrzeuge bremsten ohne Zutun des Fahrers kräftig an dieser Stelle. Warum? Der
Rundfunksender
produzierte Interferenzen mit Ihr ABS.
Bei der Implementierung von Hardwaremodulen kann man folgende Maßnahmen einsetzen, um Entwicklungsfehler zu vermeiden:
-
Einfachheit
-
Keine komplexen Optimierungen
-
Viel Luft" bei den Timing-Randbedingungen lassen
-
Nicht zu viel reinquetschen
-
Synchrones Design
-
Statisches Design (immer wenn möglich)
-
Gründliche Simulation
-
Verifikation durch Model-checking [formal]
Und solche, um Laufzeitfehler zu vermeiden:
-
Benutzen von sichersten und zuverlässigsten Komponenten
-
Niedrige Busbelastung
-
Wenige Stecker
-
Abschirmen (s. 2.)
-
So viel wie möglich in Chips integrieren (s. 1.)
-
Benutzen von gesicherten Verfahren der Hardwareintegration
-
Die Hardware wird in physikalische Module aufgeteilt (s. 2.)
-
Ausfälle der ersten Betriebsstunden vor dem Betrieb abfangen (s. 3.)
1. Die Integration in Chips erhöht die Sicherheit, denn Chips sind sicherer (und billiger) als Kabel, Verbindungen und Platinen.
2. Die Hardware wird in physikalische Module aufgeteilt, um die erwarteten Interferenzen (Funk-, Wärme- und andere Formen von Strahlung) zu reduzieren, sowie zur Stabilisierung ihrer Versorgungsspannungen. Die Module sollten abgeschirmt werden, inklusive Leitungen und Verbindungen. Es ist empfehlenswert bei Platinen die oberste und unterste Layer als Ground-Layer auszuführen, um die internen Verbindungen abzuschirmen.
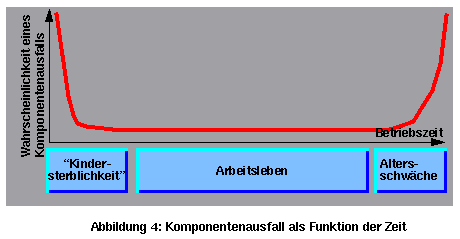
3. Viele Hardwareausfälle treten entweder in den ersten Betriebsstunden oder nach sehr langer Betriebszeit auf (siehe Abbildung 4). Bei sicherheitskritischen Systemen werden Ausfälle in der Altersschwäche-Phase durch regelmäßige Wartung und Überholungen, wie z.B. bei den Flugzeugen, minimiert. Die Ausfälle in der "Kindersterblichkeitsphase" werden durch ein "Burn-in"-Verfahren minimiert. Dabei werden die elektronischen Komponenten bei ca. 100 Grad über 24 Stunden betrieben. Hierbei fallen viele der schwachen Komponenten aus, und es bleiben fast nur die, die ihr Arbeitsleben anfangen können.
Bei der Implementierung von Softwaremodulen kann man folgende Maßnahmen einsetzen, um Entwicklungsfehler zu vermeiden:
-
Modularisierung und Trennung von sicherheitsrelevanten Anteilen
-
Vorsicht mit Überlauf bei Variablen, die ständig inkrementiert werden
-
Keine komplexen Optimierungen, einfach und direkt programmieren
-
Alle Variablen initialisieren
-
Aussagekräftige Kommentare und Referenzen zu den Anforderungen schreiben
-
Anwendung von fachgebietsspezifischen CASE-Werkzeugen, nicht nur allgemeine CASE
-
Zuerst Denken, danach Programmieren; nicht einfach hacken
-
Robuste, defensive Programmierung (s. 1.)
-
Ausnahmebehandlung von internen Fehlern (s. 2.)
-
Mögliche Fehlermeldungen oder Rückgabewerte niemals ignorieren (s. 2.)
-
Inputs müssen immer überprüft werden (s. 1.)
-
Inneres Modell mit der Realität vergleichen (s. 3.)
-
Anwendung einer sicheren Programmiersprache (s. 4.)
-
Restriktionen bei der Speicherverwaltung beachten (s. 5.)
1. Die robusten Software-Module sollen mögliche Bedienungsfehler sowie eigene Fehler abfangen (robuste, defensive Programmierung). Wichtig dabei sind die Signale (Software Interrupts) aus dem Betriebssystem. Dadurch signalisiert das Betriebssystem, daß es einen Fehler bei der Programmausführung erkannt hat, den das Programm selbst nicht bemerkt hat, z.B. Adressraumverletzungen oder Division durch Null. Wenn das Programm diese Signale nicht abfängt, wird es vom Betriebssystem abgebrochen. Dies ist ziemlich das schlimmste, was passieren kann, denn das System bleibt ohne Steuerung.
2. Bei den sicherheitskritischen Anwendungen geschehen die meisten Ausfälle durch Schnittstellenfehler. Um sich dagegen zu schützen, müssen Sie davon ausgehen, daß 1. Ihre Funktion mit falschen Parametern aufgerufen wird, 2. Ihre Fehlermeldungen ignoriert werden, und 3. die Funktionen, die Sie aufrufen, Fehler produzieren werden. Es ist empfehlenswert, 1. Strong Prototyping der Funktionen zu benutzen (z.B. Java, C++). Dokumentieren Sie mit Beispielen die Benutzung Ihrer Funktionen, so daß man die Beispiele mit Cut-and-Paste in die Applikation kopieren kann. 2. Machen Sie es schwierig, Ihre Fehlermeldungen zu ignorieren, z.B. nicht einfach als ein Return-Wert sondern Throw & Catch in Java und einigen C++ Dialekten. 3. Ignorieren Sie nicht die möglichen Fehlermeldungen von den untergeordneten Modulen.
3. Die Software soll ständig das innere Modell gegen die Realität abgleichen. Beispiel: Wenn die Steuerung der Meinung ist, das Entleerungsventil sei geöffnet, soll sie kontrollieren, ob der Wasserstand sinkt. Wenn nicht, dann stimmt etwas mit ihrem internen Modell der Anlage nicht. Oder wenn die Steuerung der Meinung ist, die Tür sei offen, und es kommt ein Signal, daß die Tür soeben geöffnet wurde, dann stimmt wiederum etwas nicht.
4. Bei der Entwicklung sicherheitsrelevanter eingebetteter Systeme ist ADA mit Abstand die vorgezogene (geeignetste) Programmiersprache. Dennoch beharren viele Entwickler auf C und C++, obwohl diese Sprachen allgemein als unsicherer eingestuft werden. Die Sprache Java vereinigt Sicherheit mit der geliebten C-(und C++) Syntax. Aber noch sind einige Steine aus dem Weg zu räumen, bevor Java für eingebettete Realzeitsysteme geeignet ist. Wenn Sie trotzdem C oder C++ benutzen, sollten Sie weitgehend auf Pointerarithmetik verzichten. Sie sollten Werkzeuge einsetzen, die Ihre Quelltexte genauer prüfen als der C/C++Compiler: Pointerplausibilität, Initialisierung der Variablen, Type-Check u.a. (z.B. das Purify Werkzeug).
5. Bei den sicherheitskritischen Programmen gibt es Restriktionen bei der Speicherverwaltung:
5.1. Es ist empfehlenswert, alle Ressourcen und Speicherbereiche von Anfang an bei der Systeminitialisierung zu alloziieren und reservieren. Dies erspart das Risiko, daß die Ressourcen nicht vorhanden sind, wenn man sie braucht. Leider ist das nicht immer möglich; bei großen Systemen oder bei dynamischen Strukturen kann man nicht im voraus alles reservieren.
5.2. Bei Echtzeitsystemen sollte man auf Garbage-collection verzichten, denn ihre Funktion und Timing sind indeterministisch. Man kann nicht wissen, wann der Garbage-collector aktiviert wird und für wie lange.
5.3. Bei Systemen, die sehr lange Zeit (Jahre) ununterbrochen laufen sollen, bringt eine dynamische Speicher-Alloziierung das Fragmentationsproblem. Es kann vorkommen, daß genügend freier Speicher vorhanden ist, aber nur in kleinen Stückchen, die man nicht benutzen kann. Eine Lösung dafür ist die Benutzung von Blöcken nur mit festen Größen. Diese Methode wird von vielen Echtzeit-Betriebssystemen zur Verfügung gestellt.
Viele der Entwicklungsfehler liegen bei der Systemintegration. Wenn viele Module zusammengeschaltet werden, können neue Probleme entstehen. Jedes Modul kann z.B. alleine seine Aufgabe erfüllen, aber alle zusammen nicht mehr. Diese Probleme kommen meistens aus Mißverständnissen an den Schnittstellen. Solche Intermodulkommunikationsfehler können das System in undefinierte Zustände bringen, die sehr schwer zu finden sind. Gegen solche Fehler helfen die Erstellung von Prototypen und/oder Simulation, da sie eine bessere Kommunikation zwischen den Entwicklern fördern.
Oft entstehen bei der Integration einfache kleine Fehler mit großen Auswirkungen. Beispiel: eine Vertauschung von Gas und Bremse bei der Verkabelung. Diese Fehler werden erst beim Testen gefunden und sind kaum zu vermeiden. Sehr oft erwachsen Katastrophen aus läppischen Fehlern, weil manche Fälle so einfach sind, daß keiner einen zweiten Gedanken daran verschwenden will. Beispiel: Wenn bei der Beschriftung der Bedienungskonsole Min und Max vertauscht werden, kann dadurch ein "Bedienungsfehler" mit katastrophalen Folgen entstehen. Solche Fehler können weder mit formalen Methoden noch mit diversitärer Entwicklung noch mit anderen raffinierten Techniken vermieden werden. Da hilft nur, doch einen zweiten Gedanken in die einfachen Sachen zu investieren.
Trotz all dieser Versuche, Fehler zu vermeiden, werden immer welche übrig bleiben. Während die Zuverlässigkeit von einfachen Maschinen sich durch Prüfungen und Tests ermitteln läßt, ist die Beurteilung der Sicherheit von softwaregesteuerten Maschinen mit komplexem Verhalten äußerst schwierig. Hier können Tests nur das Vorhandensein von Fehlern beweisen, nicht aber deren Abwesenheit. Es ist nicht realisierbar, alle möglichen Systemzustände (mit der Zeit als Teilzustand), ihre Kombinationen und Reihenfolgen durchzuspielen. Auch können Tests nicht immer unter allen möglichen oder erwarteten realistischen Bedingungen durchgeführt werden. Es kann nicht vollständig verifiziert werden, ob der Entwurf eine richtige Umsetzung der Anforderungen ist und ob Programmcode und Hardware eine richtige Umsetzung des Entwurfes sind. Jedoch kann man mit systematischen Tests versuchen, relevante Zustandsreihenfolgen zu identifizieren, zu minimieren und durchzuspielen.
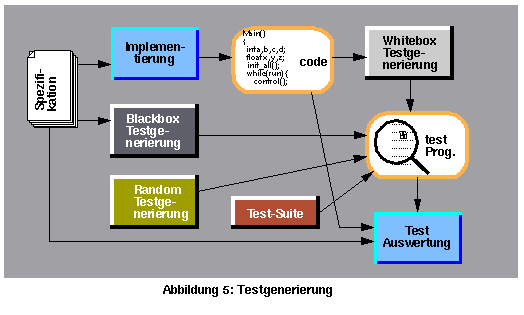
Es gibt zwei komplementäre Kategorien von Tests (Abbildung 5): Blackbox und Whitebox.
Der Blackboxtest wird nur anhand der Spezifikation generiert. Er berücksichtigt nicht die Implementierungsdetails. Dabei wird die Funktion des gesamten Systems getestet, ohne implementierungskritische Aspekte genauer zu untersuchen. Ein Teil des Blackboxtests ist die Sensibilitätsanalyse der Output-Signale. Dabei wird getestet, wie empfindlich ein Output auf die verschiedenen Input-Werte und internen Zustände des Programms reagiert.
Der Whiteboxtest berücksichtigt nur die Implementierung, ohne die gesamte Funktion zu untersuchen. Besonders wichtig sind die Grenzwerte, z.B. bei einem FIFO mit 20 Plätzen wird das Verhalten des Systems bei 0, 1, 2, 19, 20 und 21 belegten Plätzen im FIFO getestet.
Bei jedem Entwicklungsschritt, Programmteil und jeder Hardwarekomponente denkt man automatisch an Sachen, die getestet werden sollen. Man kann gleich das passende Testprogramm schreiben und aufbewahren. Alle diese Programme zusammen bilden eine Test- oder Validierungs-Suite. Diese Suite wird ständig erweitert. Bei jedem Durchlauf sollten die Ergebnisse aufbewahrt werden, um sie automatisch mit den Ergebnissen von nachfolgenden Tests vergleichen zu können. Eine manuelle Bewertung der Testergebnisse ist dann nur für die Ergebnisse der neuen Testprogramme erforderlich. Es ist wichtig, auch alte Dinge, die bereits getestet wurden, wieder zu testen, weil Änderungen und Erweiterungen Nebenwirkungen bei den bereits laufenden Teilen haben können.
Und schließlich, wenn man nicht mehr weiß, was man testen soll, kann man Tests mit Zufallsgrößen durchführen. So ein Test ist nicht so realitätsfern, wie man auf den ersten Blick denken könnte. Dabei werden immer wieder Fälle und Fehler entdeckt, an die keiner gedacht hat und die trotzdem existieren.
Die Testergebnisse müssen natürlich ausgewertet werden. Bei der Verwendung von formalen Methoden [Formale Methoden] kann man die Reaktion des Systems semiautomatisch gegen die Spezifikation vergleichen. Weiterhin sollte man eine Test-Coverage-Analyse durchführen. Diese Analyse kann vollautomatisch mit Werkzeugen geschehen. Beim Programmcode wird untersucht, ob alle Programmfäden durchgelaufen sind (sequentielle Blocks, Schleifen und if-then-else). Bei der Hardwaresimulation wird geprüft, ob alle Flip-Flops, Gatter, Buffer usw. einmal Eins und einmal Null waren. Dies ist hilfreich, um die Qualität unserer Tests zwar nur grob, aber besser als gar nicht zu bewerten.
Nach der Lieferung des Systems fängt die "echte Testphase" unter realen Bedingungen an. Alles davor waren nur simulierte Bedienungen, die nur auf Annahmen basieren und deshalb falsch sein können. Viele Entwicklungsfehler kommen aus unbekannten oder ungenannten Situationen der realen Welt. Die meisten entstehen durch falsche Annahmen, und dadurch entspricht die Spezifikation nicht der Realität. Das Problem wird weiter verschärft, weil die Umstände in der Umgebung nicht alle vorhersehbar sind. Die Korrektur der in dieser Phase gefundenen Fehler erfordert einen enormen Aufwand. Nach jeder Korrektur (Änderung) sollte erneut der gesamte Test durchgeführt werden. Dieser Aufwand ist so enorm, daß es besser ist, Fehler zu sammeln, alle zusammen zu korrigieren und erst dann alle Änderungen auf einmal erneut zu testen.
Große Systeme haben bekannte Fehler, deren Korrektur man sich nicht leisten kann: zu viel Risiko, zu hohe Kosten usw. Es ist dann besser, mit diesen Fehlern zu leben und sie als Teil der Fehlertoleranz-Mechanismen aufzufangen und zu behandeln. Dies ist der Fall bei vielen der größten Telefonnetze der Welt.
Die Korrekturen können auch ein gefährliches Spiel werden. Bei komplexen Systemen, wo eine Änderung sehr umfangreich werden kann, kann man nicht ahnen, was für weitere Folgen die Korrektur bringt (z.B. ein Fehler wird korrigiert und zwei neue schleichen sich ein). In diesem Fall gilt: Zwei wohlbekannte Fehler sind besser als ein unbekannter. Von einem bekannten Fehler weiß man, wann er eintritt und wie man ihn umgehen kann. Man kann die Operatoren warnen und vorbereiten. Bei einem unbekannten Fehler wird sein Eintritt eine böse Überraschung sein, die Gefahr lauert im Verborgenen wie in einem Hinterhalt. Deswegen hat man bei sehr komplexen Systemen das Dilemma, ob ein Fehler korrigiert werden soll, oder ob man lieber damit lebt. Beispiel: Einmal lehnte ein Flugzeug den Befehl des Piloten ab, die Bremsklappen der Triebwerke auszufahren. Es war der Meinung, es sei noch nicht auf dem Boden, obwohl es schon gelandet war. Die Landebahn war so glatt, daß die Räder sich nicht mit der erwarteten Geschwindigkeit drehten. Außerdem war es so windig, daß das Flugzeug nicht richtig aufsetzen konnte. Dadurch rutschte es aus der Landebahn. Der Flugzeughersteller scheute die Konsequenzen solch einer umfangreichen Änderung und zog es vor, lediglich die Parameter der entsprechenden Sicherheitsfunktion extrem niedrig zu setzen.
Nicht nur bei jeder Änderung soll das System unter den aktuellen realen Bedingungen erneut getestet werden, sondern auch jedesmal, wenn man neue oder geänderte Bedingungen hat. Man darf nicht denken, daß ein getestetes System überall gleich arbeiten wird, oder daß die Wiederverwendung von bereits bewährter Software oder anderen Komponenten eine sichere Sache sei. Zwei Beispiele:
1. Ein 100-fach erprobtes und bewährtes amerikanisches Luftraumkontrollsystem wurde in England installiert und verhielt sich extrem merkwürdig. Auf dem Monitor verschwanden Flugzeuge und tauchten woanders wieder auf. Das Problem war der Nullmeridian, der über England geht. In den USA brauchte man diesen Sonderfall nicht zu berücksichtigen.
2. Die bewährte Steuerungssoftware aus der Ariane-4 wurde auf die Ariane-5 übertragen. 40 Sekunden nach den Start produzierte der Fligth Control Computer (FCC) einen fatalen Fehler und die Rakete wurde vernichtet. Das Problem bestand darin, daß für die Steuerung kritische Annahmen über das Verhalten der Ariane-4-Raketen nicht dokumentiert waren und sie galten auch nicht bei der Ariane-5. Nebenbei, das Grundproblem im ersten Fall waren ebenfalls undokumentierte Annahmen, und noch mehr als das, die Annahmen waren nicht einmal bewußt.
Weitere Referenzen
Mein Buch: Sichere und Fehlertolerante Steuerungen